Låt oss försöka avgöra hur man kan öka prestandan för en applikationsserver baserad på php-fpm, och även skapa en checklista för att kontrollera fpm-processkonfigurationen.
Först och främst bör du bestämma platsen för poolkonfigurationsfilen. Om du installerade php-fpm från systemförvaret, då poolkonfigurationen www kommer att finnas ungefär här /etc/php5/fpm/pool.d/www.conf . Om du använder din egen version eller ett annat operativsystem (inte debian), bör du leta efter filplatsen i dokumentationen, eller ange den manuellt.
Låt oss försöka titta på konfigurationen mer detaljerat.
Byter till UNIX-uttag
Förmodligen är det första du bör vara uppmärksam på hur data flödar från webbservern till dina PHP-processer. Detta återspeglas i lyssningsdirektivet:
lyssna = 127.0.0.1:9000
Om adress:port är inställt går data genom TCP-stacken, och detta är förmodligen inte särskilt bra. Om det finns en väg till uttaget, till exempel:
lyssna = /var/run/php5-fpm.sock
sedan går data genom en unix-socket, och du kan hoppa över det här avsnittet.
Varför är det fortfarande värt att byta till ett unix-uttag? UDS (unix domain socket), i motsats till kommunikation via TCP-stacken, har betydande fördelar:
- kräver inte kontextbyte, UDS använder netisr)
- UDS-datagram skrivs direkt till destinationsuttaget
- att skicka ett UDS-datagram kräver färre operationer (inga kontrollsummor, inga TCP-rubriker, ingen routing)
TCP genomsnittlig latens: 6 us UDS genomsnittlig latens: 2 us PIPE genomsnittlig latens: 2 us TCP genomsnittlig genomströmning: 253702 msg/s UDS genomsnittlig genomströmning: 1733874 msg/s PIPE genomsnittlig genomströmning: 1682796 msg/s
Således har UDS en fördröjning på ~66 % mindre och genomströmning in 7 gånger mer TCP. Därför är det med största sannolikhet värt att byta till UDS. I mitt fall kommer socket att finnas på /var/run/php5-fpm.sock.
; Låt oss kommentera detta - lyssna = 127.0.0.1:9000 lyssna = /var/run/php5-fpm.sock
Du bör också se till att webbservern (eller någon annan process som behöver kommunicera) har läs-/skrivåtkomst till din socket. Det finns inställningar för detta lyssna.grupp Och lyssna.läge Det enklaste sättet är att köra båda processerna från samma användare eller grupp, i vårt fall kommer php-fpm och webbservern att startas med gruppen www-data:
listen.owner = www-data listen.group = www-data listen.mode = 0660
Kontrollerar den valda händelsebearbetningsmekanismen
För att arbeta effektivt med I/O (ingång/utgång, fil-/enhets-/uttagsbeskrivningar) är det värt att kontrollera om inställningen är korrekt angiven händelser.mekanism. Om php-fpm är installerat från systemförvaret är troligtvis allt bra där - det är antingen inte specificerat (installerat automatiskt) eller specificerat korrekt.
Dess betydelse beror på operativsystemet, för vilket det finns en ledtråd i dokumentationen:
; - epoll (linux >= 2.5.44); - kqueue (FreeBSD >= 4.1, OpenBSD >= 2.9, NetBSD >= 2.0) ; - /dev/poll (Solaris >= 7) ; - port (Solaris >= 10)
Om vi till exempel arbetar med en modern Linux-distribution behöver vi epool:
händelser.mekanism = epoll
Välja en pooltyp - dynamisk / statisk / ondemand
Det är också värt att uppmärksamma inställningarna för processhanteraren (pm). I huvudsak är detta huvudprocessen, som kommer att hantera alla sina barn (som exekverar applikationskoden) enligt en viss logik, som faktiskt beskrivs i konfigurationsfilen.
Det finns totalt 3 processkontrollscheman tillgängliga:
- dynamisk
- statisk
- på begäran
Den enklaste är statisk. Så här fungerar det: starta ett fast antal underordnade processer och håll dem i fungerande skick. Detta driftschema är inte särskilt effektivt, eftersom antalet förfrågningar och deras belastning kan ändras från tid till annan, men antalet underordnade processer gör det inte - de upptar alltid en viss mängd RAM och kan inte behandla toppbelastningar i en kö.
dynamisk en pool kommer att lösa detta problem; den reglerar antalet underordnade processer baserat på värdena i konfigurationsfilen, ändrar dem uppåt eller nedåt, beroende på belastningen. Den här poolen är mest lämplig för en applikationsserver som kräver ett snabbt svar på förfrågningar, arbetar med toppbelastningar och som kräver besparingar av resurser (genom att minska underordnade processer när de är inaktiva).
på begäran pool är mycket lik statisk, men den startar inte underordnade processer när huvudprocessen startar. Först när den första begäran kommer kommer den första underordnade processen att skapas, och efter en viss väntetid (anges i konfigurationen) kommer den att förstöras. Därför är det relevant för servrar med begränsade resurser, eller för logik som inte kräver snabb respons.
Minnesläckor och OOM-dödare
Du bör vara uppmärksam på kvaliteten på applikationer som kommer att köras av underordnade processer. Om kvaliteten på applikationen inte är särskilt hög, eller många tredjepartsbibliotek används, måste du tänka på möjliga minnesläckor och ställa in värdena för sådana variabler:
- pm.max_requests
- request_terminate_timeout
pm.max_requests detta är det maximala antalet förfrågningar som den underordnade processen kommer att bearbeta innan den avlivas. Påtvingad förstörelse av processen gör att du kan undvika en situation där minnet av barnprocessen "sväller" på grund av läckor (eftersom processen fortsätter att fungera efter begäran efter begäran). Å andra sidan kommer ett värde som är för litet att resultera i frekventa omstarter, vilket resulterar i prestandaförluster. Det är värt att börja med ett värde på 1000 och sedan minska eller öka detta värde.
request_terminate_timeout anger den maximala tid som en underordnad process kan köras innan den avlivas. Detta låter dig undvika långa frågor om värdet för max_execution_time i tolkinställningarna av någon anledning ändrades. Värdet bör ställas in baserat på logiken i de applikationer som bearbetas, till exempel 60-tal(1 minut).
Att skapa en dynamisk pool
För huvudapplikationsservern, på grund av uppenbara fördelar, väljs ofta en dynamisk pool. Dess funktion beskrivs av följande inställningar:
- pm.max_barn- maximalt antal underordnade processer
- pm.start_servers- antal processer vid uppstart
- pm.min_spare_servers- det minsta antalet processer som väntar på anslutningar (förfrågningar om bearbetning)
- pm.max_spare_servers- maximalt antal processer som väntar på anslutningar (förfrågningar som ska behandlas)
För att ställa in dessa värden korrekt är det nödvändigt att överväga:
- hur mycket minne förbrukar en barnprocess i genomsnitt?
- mängd tillgängligt RAM
Du kan ta reda på det genomsnittliga minnesvärdet per en php-fpm-process på en applikation som redan körs med hjälp av schemaläggaren:
# ps -ylC php-fpm --sort:rss S UID PID PPID C PRI NI RSS SZ WCHAN TTY TIME CMD S 0 1445 1 0 80 0 9552 42588 ep_pol ? 00:00:00 php5-fpm
Vi behöver medelvärdet i RSS-kolumnen (resident memory size i kilobyte). I mitt fall är det ~20MB. Om det inte finns någon belastning på applikationer kan du använda Apache Benchmark för att skapa en enkel belastning på php-fpm.
Mängden totalt / tillgängligt / använt minne kan ses med fri:
# ledig -m totalt använd ledig ... Minne: 4096 600 3496
Totalt maxprocesser = (Totalt ramminne - (använd ram + buffert)) / (minne per php-process) Totalt RAM-minne: 4GB använt RAM-minne: 1000MB Säkerhetsbuffert: 400MB Minne per barn php-fpm-process (i genomsnitt): 30MB Maximalt möjligt antal av processer = (4096 - (1000 + 400)) / 30 = 89 Jämnt antal: 89 avrundade nedåt till 80
Värdet på de återstående direktiven kan ställas in baserat på den förväntade belastningen på applikationen och även ta hänsyn till vad mer servern gör förutom att köra php-fpm (till exempel kräver DBMS också resurser). Om det finns många uppgifter på servern är det värt att minska antalet initiala / maximala processer.
Låt oss till exempel ta hänsyn till att det finns 2 pooler www1 och www2 på servern (till exempel 2 webbresurser), då kan konfigurationen för var och en av dem se ut så här:
pm.max_children = 40 ; 80 / 2 pm.start_servers = 15 pm.min_spare_servers = 15 pm.max_spare_servers = 25
Om du har utvecklat PHP under de senaste åren är du förmodligen medveten om språkets problem. Du kommer ofta att höra att det är ett fragmenterat språk, ett hackverktyg, att det inte har någon riktig specifikation osv. Verkligheten är att PHP har vuxit mycket på sistone. PHP 5.4 förde den närmare en komplett objektmodell och introducerade en hel del ny funktionalitet.
Och det här är förstås bra, men hur är det med ramar? Det finns ett stort antal av dem i PHP. När du väl börjar leta kommer du att inse att du inte kommer att ha tillräckligt med tid att studera dem alla, eftersom nya ramverk dyker upp hela tiden och något annat uppfinns i var och en. Så hur gör du detta till något som inte alienerar utvecklare och gör att funktionalitet enkelt kan porteras från ett ramverk till ett annat?
Vad är PHP-FIG
PHP-FIG (PHP Framework Interop Group) är en organiserad grupp av utvecklare vars mål är att hitta sätt för flera ramverk att fungera tillsammans.
Föreställ dig bara: du stöder för närvarande ett Zend Framework-projekt som behöver en butiksvagnsmodul. Du har redan skrivit en sådan modul för ett tidigare projekt, som låg på Symphony. Varför inte göra det igen? Lyckligtvis är både ZendF och Symphony en del av PHP-FIG, så det är möjligt att importera en modul från ett ramverk till ett annat. Är det inte bra?
Låt oss ta reda på vilka ramverk som ingår i PHP-FIG
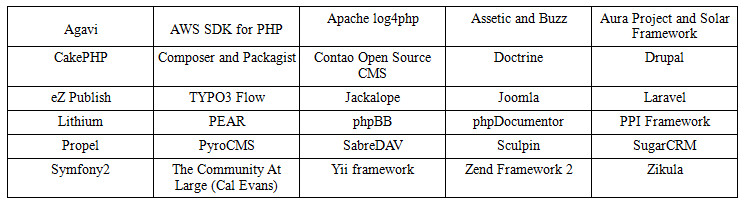
PHP-FIG medlemmar
Alla utvecklare kan lägga till sitt ramverk till listan över PHP-FIG-deltagare. Du kommer dock att behöva betala lite pengar för att göra detta, så om du inte har stöd från samhället kommer du sannolikt inte att gå med på det. Detta görs för att förhindra att miljontals mikroframeworks registreras utan rykte.
Nuvarande medlemmar:
Vad är PSR?
PSR (PHP Standards Recommendations) - standardrekommendationer, resultatet av arbetet med PHP-FIG. Vissa medlemmar i gruppen föreslår regler för varje PSR, medan andra röstar för att stödja eller eliminera reglerna. Diskussion äger rum i Google Groups och PSR-set finns på den officiella PHP-FIG-webbplatsen.
Låt oss titta på några PSR:
Det första steget mot att förena ramverk är att ha en gemensam katalogstruktur, varför en gemensam startstandard antogs.
- Namnutrymmet och klassen måste ha strukturen \\(\)*.
- Varje namnområde måste innehålla ett utrymme på toppnivå ("Leverantnamn").
- Varje namnområde kan ha så många nivåer som önskas.
- Varje namnområdesavgränsare konverteras till DIRECTORY_SEPARATOR när den läses in.
- Varje "_" tecken i CLASS NAME konverteras till DIRECTORY_SEPARATOR.
- Det fullt kvalificerade namnutrymmet och klassen läggs till med ".php" när de laddas.
Exempel på autoload-funktion:

PSR-1 - Grundläggande kodningsstandard
Dessa PSR:er reglerar kärnstandarder, vars huvudidé är att om alla utvecklare använder samma standarder kan kod porteras utan problem.
- Filer får endast använda taggar
- Filer får endast använda UTF-8-kodning utan BOM.
- Utrymmesnamn och klasser måste följa PSR-0.
- Klassnamn måste deklareras i StudlyCaps-notation.
- Klasskonstanter måste deklareras med stora bokstäver, åtskilda av understreck.
- Metoder måste deklareras i camelCase-notation.
PSR-2 - Coding Style Guide
Dessa är utökade instruktioner för PSR-1 som beskriver kodformateringsregler.
- Koden måste överensstämma med PSR-1.
- 4 mellanslag bör användas istället för flikar.
- Det bör inte finnas någon strikt gräns för radlängden, den rekommenderade längden är upp till 80 tecken.
- Det ska finnas en tom rad efter namnområdesdeklarationen.
- Parenteser för klasser ska öppnas på nästa rad efter deklarationen och stängas efter klasskroppen (samma för metoder).
- Synligheten av metoder och egenskaper måste definieras (offentliga, privata).
- Öppnande konsoler för kontrollkonstruktioner måste vara på samma linje, stängningskonsoler måste vara på nästa rad efter strukturens kropp.
- Mellanslag placeras inte efter de inledande parenteserna för kontrollstrukturmetoder och före de avslutande parenteserna.
PCR-3 - Loggergränssnitt
PCR-3 reglerar loggning, särskilt de nio huvudsakliga metoderna.
- LoggerInterface tillhandahåller 8 metoder för att logga åtta RFC 5424-nivåer (felsökning, meddelande, varning, fel, kritisk, varning, nödsituation).
- Den nionde metoden log() tar varningsnivån som sin första parameter. Att anropa en metod med en larmnivåparameter måste returnera samma resultat som att anropa en metod på en specifik loggnivå (log(ALERT) == alert()). Att anropa en metod med en odefinierad varningsnivå måste ge ett Psr\Log\InvalidArgumentException.
Precis som PSR-0 erbjuder PSR-4 förbättrade metoder för automatisk laddning
- Termen "klass" syftar på klasser, gränssnitt, egenskaper och andra liknande strukturer
- Det fullt kvalificerade klassnamnet har följande form: \
(\ )*\ - När du laddar en fil som matchar ett fullt kvalificerat klassnamn:
- En sammanhängande serie av ett eller flera ledande namnutrymmen, utan den ledande namnutrymmesavgränsaren, i ett fullt kvalificerat klassnamn motsvarar minst en "rotkatalog".
- Katalog- och underkatalognamn måste matcha namnområdets skiftläge.
- Slutet på det fullständiga klassnamnet motsvarar filnamnet som slutar på .php. Versalerna i filnamnet måste matcha skiftlägena för slutet av det fullständiga klassnamnet.
- En autoloaderimplementering får inte ge undantag, generera fel på någon nivå och behöver inte returnera ett värde.
Slutsats
PHP-FIG ändrar hur ramverk skrivs, men inte hur de fungerar. Kunder kräver ofta att du arbetar med befintlig kod inom ett ramverk eller bestämmer vilket ramverk du ska arbeta med i ett projekt. PSR-rekommendationer gör livet mycket lättare för utvecklare i detta avseende och det är bra!
1. GRUPPERA MED en knapp
Denna funktion fungerar som GROUP BY för array, men med en viktig begränsning: Endast en gruppering "kolumn" ($identifier) är möjlig.
Funktion arrayUniqueByIdentifier(array $array, string $identifier)( $ids = array_column($array, $identifier); $ids = array_unique($ids); $array = array_filter($array, funktion ($key, $value) ) använd ($ids) (retur in_array($value, array_keys($ids)); ), ARRAY_FILTER_USE_BOTH); return $array;)
2. Identifiera de unika raderna för en tabell (tvådimensionell array)
Denna funktion är till för att filtrera "rader". Om vi säger att en tvådimensionell matris är en tabell, så är varje element en rad. Så vi kan ta bort de dubblerade raderna med den här funktionen. Två rader (element i den första dimensionen) är lika, om alla deras kolumner (element i den andra dimensionen) är lika. För jämförelsen av "kolumn"-värden gäller: Om ett värde är av en enkel typ, kommer själva värdet att användas vid jämförelse; annars kommer dess typ (array , objekt , resurs , okänd typ) att användas.
Strategin är enkel: Gör från den ursprungliga arrayen en ytlig array, där elementen imploderas d "kolumner" i den ursprungliga arrayen; applicera sedan array_unique(...) på den; och använd som senast de upptäckta ID:n för filtrering av den ursprungliga arrayen.
Funktion arrayUniqueByRow(array $table = , sträng $implodeSeparator) ( $elementStrings = ; foreach ($table som $row) ( // För att undvika meddelanden som "Array till strängkonvertering". $elementPreparedForImplode = array_map(function ($field) ( $valueType = gettype($field); $simpleTypes = ["boolean", "integer", "double", "float", "string", "NULL"]; $field = in_array($valueType, $simpleTypes) ? $field: $valueType; return $field; ), $row); return $table; )
Det är också möjligt att förbättra jämförelsen, upptäcka "kolumnvärdets" klass, om dess typ är objekt.
$implodeSeparator borde vara mer eller mindre komplex, z.B. spl_object_hash($this) .
3. Upptäcka raderna med unika identifierarkolumner för en tabell (tvådimensionell array)
Denna lösning förlitar sig på den 2:a. Nu behöver inte hela "raden" vara unik. Två "rader" (element av den första dimensionen) är lika nu, om alla relevant"fält" (element i den andra dimensionen) i den ena "raden" är lika med motsvarande "fält" (element med samma nyckel).
De "relevanta" "fälten" är "fälten" (element i den andra dimensionen), som har nyckel, som är lika med ett av elementen i de godkända "identifierarna".
Funktion arrayUniqueByMultipleIdentifiers(array $table, array $identifiers, string $implodeSeparator = null) ( $arrayForMakingUniqueByRow = $removeArrayColumns($table, $identifiers, true); $arrayUniqueByRow = $arrayKingUniqueByParray($arrayUniqueByRow); rayUniqueByMultipleI identifierare = array_intersect_key ($table, $arrayUniqueByRow); return $arrayUniqueByMultipleIdentifiers; ) funktion removeArrayColumns(array $table, array $columnNames, bool $isWhitelist = false) (foreach ($tabell som $rowKey => $row) rad )) ( if ($isWhitelist) ( foreach ($row as $fieldName => $fieldValue) (if (!in_array($fieldName, $columnNames)) ( unset($table[$rowKey][$fieldName] ); ) ) ) else ( foreach ($row som $fieldName => $fieldValue) (if (in_array($fieldName, $columnNames)) ( unset($table[$rowKey][$fieldName]); ) ) ) ) returnera $-tabellen;)
Sedan teknikutvecklingen har lett till att varje programmerare nu har sin egen dator, som en bieffekt har vi tusentals olika bibliotek, ramverk, tjänster, API:er osv. för alla tillfällen. Men när detta fall av liv kommer, uppstår ett problem - vad man ska använda och vad man ska göra om det inte riktigt passar - skriv om det, skriv ditt eget från början eller bifoga flera lösningar för olika användningsfall.
Jag tror att många har märkt att det ofta handlar om att skapa ett projekt inte så mycket på programmering som att skriva kod för att integrera flera färdiga lösningar. Ibland blir sådana kombinationer till nya lösningar som kan användas upprepade gånger i efterföljande problem.
Låt oss gå vidare till en specifik "körande" uppgift - ett objektlager för att arbeta med databaser i PHP. Det finns ett stort utbud av lösningar, allt från PDO till multi-level (och, enligt min mening, inte helt lämpliga i PHP) ORM-motorer.
De flesta av dessa lösningar migrerade till PHP från andra plattformar. Men ofta tar författare inte hänsyn till funktionerna i PHP, vilket skulle förenkla både skrivning och användning av porterade konstruktioner avsevärt.
En av de vanliga arkitekturerna för denna klass av uppgifter är Active Record-mönstret. I synnerhet används denna mall för att bygga så kallade Entities, som används i en eller annan form i ett antal plattformar, allt från persistenta bönor i EJB3 till EF i .NET.
Så låt oss bygga en liknande konstruktion för PHP. Låt oss kombinera två coola saker - det färdiga ADODB-biblioteket och de svagt typade och dynamiska egenskaperna hos PHP-språkobjekt.
En av de många funktionerna i ADODB är den så kallade autogenereringen av SQL-frågor för att infoga (INSERT) och uppdatera (UPDATE) poster baserat på associativa arrayer med data.
Egentligen finns det inget militärt för att ta en array, där nycklarna är namnen på fälten och värdena är respektive data och genererar en SQL-frågesträng. Men ADODB gör det på ett smartare sätt. Frågan baseras på tabellstrukturen, som tidigare läses från databasschemat. Som ett resultat är det för det första bara befintliga fält som ingår i sql och inte allt i rad, för det andra tas hänsyn till fälttypen - citattecken läggs till för strängar, datumformat kan bildas utifrån tidsstämpel om ADODB ser det istället för en sträng i det överförda värdet etc. .
Låt oss nu gå från PHP-sidan.
Låt oss föreställa oss en sådan klass (förenklat).
Klassentitet( skyddade $fields = array(); offentlig slutfunktion __set($namn, $värde) ($this->fields[$name] = $värde; ) offentlig slutlig funktion __get($name) (retur $ detta- >fält[$namn]; ) )
Genom att skicka den interna arrayen till ADODB-biblioteket kan vi automatiskt generera SQL-frågor för att uppdatera en post i databasen med ett givet objekt.Samtidigt finns det inget behov av krångliga design för att mappa databastabellfält till XML-baserad entitet. objektfält och liknande. Det är bara nödvändigt att fältnamnet matchar objektegenskapen. Eftersom hur fälten i databasen och fälten i objektet namnges inte spelar någon roll för datorn, finns det ingen anledning för dem att inte matcha.
Låt oss visa hur det fungerar i den slutliga versionen.
Koden för den genomförda klassen finns på Gist. Detta är en abstrakt klass som innehåller det minimum som krävs för att arbeta med databasen. Jag noterar att den här klassen är en förenklad version av en lösning som har testats på flera dussin projekt.
Låt oss föreställa oss att vi har ett tecken så här:
SKAPA TABELL `users` (`användarnamn` varchar(255) , `skapat` datum , `user_id` int(11) NOT NULL AUTO_INCREMENT, PRIMARY KEY (`user_id`))
Typen av databas spelar ingen roll - ADODB ger portabilitet till alla vanliga databasservrar.
Låt oss skapa en User-entity-klass baserat på Entity-klassen
/** * @table=users * @keyfield=user_id */ class User extends Entity( )
Det är allt.
Lätt att använda:
$användare = ny användare(); $user->username="Vasya Pupkin"; $user->created=tid(); $user->save(); //save to storage //load again $thesameuser = User::load($user->user_id); echo $thesameuser ->användarnamn;
Vi anger tabellen och nyckelfältet i pseudo-annoteringar.
Vi kan också ange en vy (till exempel view =usersview) om, som ofta är fallet, enheten väljs utifrån dess tabell med bifogade eller beräknade fält. I det här fallet kommer data att väljas från vyn och tabellen kommer att uppdateras. De som inte gillar sådana anteckningar kan åsidosätta getMetatada()-metoden och specificera tabellparametrarna i den returnerade arrayen.
Vad mer är användbart med Entity-klassen i den här implementeringen?
Till exempel kan vi åsidosätta init()-metoden, som anropas efter att en Entity-instans har skapats, för att initiera det förinställda skapandedatumet.
Eller överbelasta afterLoad()-metoden, som automatiskt anropas efter att en entitet laddats från databasen, för att konvertera datumet till en tidsstämpel för ytterligare mer bekväm användning.
Som ett resultat får vi en inte mycket mer komplex struktur.
/** * @table=users * @view=usersview * @keyfield=user_id */ class User extends Entity( protected function init() ( $this->created = time(); ) protected function afterLoad() ( $this ->created = strtotime($this->created); ) )
Du kan också överbelasta beforeSave och beforeDelete-metoderna och andra livscykelhändelser där du till exempel kan utföra validering innan du sparar eller några andra åtgärder - till exempel ta bort bilder från uppladdningen när du tar bort en användare.
Vi laddar en lista över enheter efter kriterium (i huvudsak ett villkor för WHERE).
$users = User::load("användarnamn som "Pupkin" ");
Dessutom låter Entity-klassen dig exekvera en godtycklig, "native" SQL-fråga, så att säga. Vi vill till exempel returnera en lista över användare med några grupperingar baserade på statistik. Det spelar ingen roll vilka specifika fält som kommer att returneras (huvudsaken är att det ska finnas ett user_id om det finns ett behov av ytterligare manipulation av enheten), du behöver bara känna till deras namn för att komma åt de valda fälten. När du sparar en entitet, som framgår av ovanstående, behöver du inte heller fylla i alla fält som kommer att finnas i entitetsobjektet, de kommer att gå till databasen. Det vill säga att vi inte behöver skapa ytterligare klasser för stickprov. Ungefär som anonyma strukturer när man hämtar i EF, bara här är det samma entitetsklass med alla affärslogikmetoder.
Strängt taget är ovanstående metoder för att erhålla listor något utanför AR-mönstret. I huvudsak är dessa fabriksmetoder. Men som Occams gamle man testamenterade, låt oss inte skapa enheter utöver vad som är nödvändigt och skapa en separat Entity Manager eller något liknande.
Observera att ovanstående bara är PHP-klasser och de kan utökas och modifieras efter önskemål, vilket lägger till egenskaper och affärslogikmetoder till entiteten (eller basklassen Entity). Det vill säga, vi får inte bara en kopia av en databastabellrad, utan en affärsenhet som en del av applikationens objektarkitektur.
Vem kan ha nytta av detta? Naturligtvis inte för erfarna utvecklare som tror att det inte är respektabelt att använda något enklare än en doktrin, och inte för perfektionister som är övertygade om att om en lösning inte drar ut en miljard samtal till databasen per sekund, så är det inte en lösning . Att döma av forumen möter många vanliga utvecklare som arbetar med vanliga (99,9%) projekt förr eller senare problemet med att hitta ett enkelt och bekvämt objektbaserat sätt att komma åt databasen. Men de ställs inför det faktum att de flesta lösningar antingen är orimligt sofistikerade eller ingår i någon form av ramverk.
P.S. Gjorde lösningen från ramverket som ett separat projekt
PHP programmeringsspråk har kommit långt från ett verktyg för att skapa personliga sidor till ett allmänt språk. Idag är den installerad på miljontals servrar runt om i världen, som används av miljontals utvecklare som skapar en mängd olika projekt.
Det är lätt att lära sig och extremt populärt, särskilt bland nybörjare. Därför följdes språkets utveckling av en kraftfull utveckling av samhället kring det. Ett stort antal skript, för alla tillfällen, olika bibliotek, ramverk. Bristen på enhetliga standarder för design och skrivning av kod ledde till uppkomsten av ett enormt lager av informationsprodukter byggda på de egna principerna för utvecklaren av denna produkt. Detta märktes särskilt när man arbetade med olika PHP ramar, som under lång tid representerade ett slutet ekosystem, oförenligt med andra ramverk, trots att uppgifterna de löser ofta är likartade.
Under 2009 gick utvecklare av flera ramverk överens om att skapa en community PHP Framework Interop Group (PHP-FIG), som skulle utveckla rekommendationer för utvecklare. Det är viktigt att understryka att det inte handlar om ISO-standarder, är det mer korrekt att tala om rekommendationer. Men sedan de som skapade PHP-FIG Eftersom utvecklargemenskapen representerar stora ramverk väger deras rekommendationer allvarligt. Stöd PSR (PHP standard rekommendation) standarder möjliggör kompatibilitet, vilket underlättar och påskyndar utvecklingen av slutprodukten.
Totalt finns det i skrivande stund 17 standarder, 9 av dem är godkända, 8 är på utkaststadiet, diskuteras aktivt, 1 standard rekommenderas inte att användas.
Låt oss nu gå direkt till beskrivningen av varje standard. Observera att jag inte kommer att gå in i detalj om varje standard här, utan detta är en kort introduktion. Dessutom kommer artikeln bara att överväga dessa PSR-standarder, som är officiellt accepterade, dvs. är i Accepterad status.
PSR-1. Grundläggande kodningsstandard
Det representerar de mest allmänna reglerna, som att använda PHP-taggar, filkodning, separation av plats för funktionsdeklaration, klass och plats för deras användning, namn på klasser och metoder.
PSR-2. Guide för kodstil
Den är en fortsättning på den första standarden och reglerar användningen av flikar och radbrytningar i kod, maxlängden på kodrader, regler för utformning av kontrollstrukturer m.m.
PSR-3. Loggningsgränssnitt.
Denna standard är utformad för att möjliggöra (loggning) inloggning av applikationer som är inskrivna PHP.
PSR-4. Startstandard
Detta är förmodligen den viktigaste och mest nödvändiga standarden, som kommer att diskuteras i en separat, detaljerad artikel. Klasser som implementerar PSR-4, kan laddas av en enda autoloader, vilket gör att delar och komponenter från ett ramverk eller bibliotek kan användas i andra projekt.
PSR-6. Cachinggränssnitt
Cachning används för att förbättra systemets prestanda. OCH PSR-6 låter dig lagra och hämta data från cachen som standard med hjälp av ett enhetligt gränssnitt.
PSR-7. HTTP-meddelandegränssnitt
När man skriver mer eller mindre komplext webbplatser i PHP, måste man nästan alltid jobba med HTTP-rubriker. Säkert, PHP-språk ger oss färdiga alternativ för att arbeta med dem, som t.ex superglobal array $_SERVER, funktioner rubrik(), setcookie() etc., men deras manuella analys är fylld med fel, och det är inte alltid möjligt att ta hänsyn till alla nyanser av att arbeta med dem. Och så, för att göra utvecklarens arbete enklare, samt för att göra gränssnittet för att interagera med HTTP-protokoll denna standard antogs. Jag kommer att prata mer detaljerat om denna standard i en av följande artiklar.
PSR-11. Behållargränssnitt
När man skriver PHP-program Ofta måste du använda komponenter från tredje part. Och för att inte gå vilse i denna skog av beroenden uppfanns olika metoder för att hantera kodberoenden, ofta inkompatibla med varandra, vilket den här standarden ger en gemensam nämnare.
PSR-13. Hypermedialänkar
Detta gränssnitt är utformat för att underlätta utvecklingen och användningen av applikationsprogrammeringsgränssnitt ( API).
PSR-14. Enkelt cachinggränssnitt
Är en fortsättning och förbättring av standarden PSR-6
Så idag tittade vi på PSR-standarder. För uppdaterad information om status för standarder, vänligen kontakta: