Să încercăm să determinăm cum să creștem performanța unui server de aplicații bazat pe php-fpm și, de asemenea, să creăm o listă de verificare pentru verificarea configurației procesului fpm.
În primul rând, ar trebui să determinați locația fișierului de configurare a pool-ului. Dacă ați instalat php-fpm din depozitul de sistem, atunci configurația pool-ului www va fi localizat aproximativ aici /etc/php5/fpm/pool.d/www.conf . Dacă utilizați propria versiune sau un alt sistem de operare (nu Debian), ar trebui să căutați locația fișierului în documentație sau să o specificați manual.
Să încercăm să privim configurația mai detaliat.
Trecerea la socket-uri UNIX
Probabil că primul lucru la care ar trebui să acordați atenție este modul în care datele circulă de la serverul web la procesele dvs. PHP. Acest lucru se reflectă în directiva de ascultare:
asculta = 127.0.0.1:9000
Dacă adresa:port este setată, atunci datele trec prin stiva TCP, iar acest lucru probabil nu este foarte bun. Dacă există o cale către socket, de exemplu:
asculta = /var/run/php5-fpm.sock
apoi datele trec printr-un socket Unix și puteți sări peste această secțiune.
De ce mai merită să treci la un socket Unix? UDS (unix domain socket), spre deosebire de comunicarea prin stiva TCP, are avantaje semnificative:
- nu necesită schimbarea contextului, UDS folosește netisr)
- Datagrama UDS este scrisă direct în socket-ul de destinație
- trimiterea unei datagrame UDS necesită mai puține operațiuni (fără sume de control, fără antete TCP, fără rutare)
Latență medie TCP: 6 us Latență medie UDS: 2 us Latență medie PIPE: 2 us Debit mediu TCP: 253702 msg/s Debit mediu UDS: 1733874 msg/s Debit mediu PIPE: 1682796 msg/s
Astfel, UDS are o întârziere de ~66% mai puținși debitul în de 7 ori mai mult TCP. Prin urmare, cel mai probabil merită să treceți la UDS. În cazul meu, socket-ul va fi localizat la /var/run/php5-fpm.sock.
; Să comentăm asta - ascultă = 127.0.0.1:9000 ascultă = /var/run/php5-fpm.sock
De asemenea, ar trebui să vă asigurați că serverul web (sau orice alt proces care trebuie să comunice) are acces de citire/scriere la socket. Există setări pentru asta asculta.grupȘi ascultare.modul Cel mai simplu mod este să rulezi ambele procese de la același utilizator sau grup, în cazul nostru php-fpm și serverul web vor fi lansate cu grupul www-data:
listen.owner = www-data listen.group = www-data listen.mode = 0660
Verificarea mecanismului de procesare a evenimentului selectat
Pentru a lucra eficient cu I/O (descriptori de intrare/ieșire, fișier/dispozitiv/socket), merită să verificați dacă setarea este specificată corect evenimente.mecanism. Dacă php-fpm este instalat din depozitul de sistem, cel mai probabil totul este în regulă acolo - fie nu este specificat (instalat automat), fie specificat corect.
Semnificația sa depinde de sistemul de operare, pentru care există un indiciu în documentație:
; - epoll (linux >= 2.5.44) ; - kqueue (FreeBSD >= 4.1, OpenBSD >= 2.9, NetBSD >= 2.0); - /dev/poll (Solaris >= 7) ; - port (Solaris >= 10)
De exemplu, dacă lucrăm la o distribuție Linux modernă, avem nevoie de epool:
evenimente.mecanism = epoll
Selectarea unui tip de pool - dinamic / static / la cerere
De asemenea, merită să acordați atenție setărilor managerului de proces (pm). În esență, acesta este procesul principal, care își va gestiona toți copiii (care execută codul aplicației) după o anumită logică, care este de fapt descrisă în fișierul de configurare.
Există un total de 3 scheme de control al procesului disponibile:
- dinamic
- static
- la cerere
Cel mai simplu este static. Modul de funcționare este următorul: lansați un număr fix de procese copil și mențineți-le în stare de funcționare. Această schemă de operare nu este foarte eficientă, deoarece numărul de solicitări și încărcarea acestora se pot schimba din când în când, dar numărul de procese copii nu - ele ocupă întotdeauna o anumită cantitate de RAM și nu pot procesa sarcinile de vârf într-o coadă.
dinamic un pool va rezolva această problemă; reglează numărul de procese copil pe baza valorilor fișierului de configurare, modificându-le în sus sau în jos, în funcție de încărcare. Acest pool este cel mai potrivit pentru un server de aplicații care necesită un răspuns rapid la solicitări, lucrează cu sarcini de vârf și necesită economisirea resurselor (prin reducerea proceselor copil atunci când este inactiv).
la cerere piscina este foarte asemanatoare cu static, dar nu lansează procese secundare când începe procesul principal. Numai la sosirea primei cereri va fi creat primul proces copil, iar după un anumit timp de așteptare (specificat în configurație) va fi distrus. Prin urmare, este relevant pentru serverele cu resurse limitate sau pentru logica care nu necesită răspuns rapid.
Scurgeri de memorie și criminal OOM
Ar trebui să acordați atenție calității aplicațiilor care vor fi executate de procesele copil. Dacă calitatea aplicației nu este foarte ridicată sau sunt utilizate multe biblioteci terțe, atunci trebuie să vă gândiți la posibile scurgeri de memorie și să setați valorile unor astfel de variabile:
- pm.max_requests
- request_terminate_timeout
pm.max_requests acesta este numărul maxim de solicitări pe care le va procesa copilul înainte de a fi ucis. Distrugerea forțată a procesului vă permite să evitați o situație în care memoria procesului copil „se umflă” din cauza scurgerilor (deoarece procesul continuă să funcționeze după solicitare după solicitare). Pe de altă parte, o valoare prea mică va duce la reporniri frecvente, ducând la pierderi de performanță. Merită să începeți cu o valoare de 1000 și apoi să micșorați sau să creșteți această valoare.
request_terminate_timeout setează perioada maximă de timp pe care un proces copil poate rula înainte de a fi oprit. Acest lucru vă permite să evitați interogările lungi dacă din anumite motive valoarea max_execution_time din setările interpretului a fost modificată. Valoarea ar trebui să fie setată pe baza logicii aplicațiilor care sunt procesate, să zicem anii 60(1 minut).
Crearea unui bazin dinamic
Pentru serverul principal de aplicații, datorită avantajelor evidente, se alege adesea un pool dinamic. Funcționarea sa este descrisă de următoarele setări:
- pm.max_copii- numărul maxim de procese copil
- pm.start_servers- numărul de procese la pornire
- pm.min_spare_servers- numărul minim de procese care așteaptă conexiuni (cereri de procesare)
- pm.max_spare_servers- numărul maxim de procese care așteaptă conexiuni (cererile care urmează să fie procesate)
Pentru a seta corect aceste valori, este necesar să luați în considerare:
- câtă memorie consumă în medie un proces copil?
- cantitatea de memorie RAM disponibilă
Puteți afla valoarea medie a memoriei pentru un proces php-fpm pe o aplicație care rulează deja folosind planificatorul:
# ps -ylC php-fpm --sort:rss S UID PID PPID C PRI NI RSS SZ WCHAN TTY TIME CMD S 0 1445 1 0 80 0 9552 42588 ep_pol ? 00:00:00 php5-fpm
Avem nevoie de valoarea medie din coloana RSS (dimensiunea memoriei rezidente în kiloocteți). În cazul meu, este de ~20MB. Dacă nu există încărcare pe aplicații, puteți utiliza Apache Benchmark pentru a crea o încărcare simplă pe php-fpm.
Cantitatea de memorie totală/disponibilă/utilizată poate fi vizualizată folosind gratuit:
# liber -m total folosit gratuit ... Memorie: 4096 600 3496
Total max procese = (Total Ram - (Used Ram + Buffer)) / (Memorie per proces php) Total RAM: 4 GB RAM utilizat: 1000 MB Buffer de securitate: 400 MB Memorie per proces php-fpm copil (în medie): 30 MB Număr maxim posibil de procese = (4096 - (1000 + 400)) / 30 = 89 Număr par: 89 rotunjit în jos la 80
Valoarea directivelor rămase poate fi setată în funcție de încărcarea așteptată a aplicației și, de asemenea, să ia în considerare ce altceva face serverul în afară de rularea php-fpm (de exemplu, DBMS necesită și resurse). Dacă există multe sarcini pe server, merită să reduceți numărul de procese inițiale / maxime.
De exemplu, să luăm în considerare faptul că există 2 pool-uri www1 și www2 pe server (de exemplu, 2 resurse web), atunci configurația fiecăruia dintre ele poate arăta astfel:
pm.max_copii = 40 ; 80 / 2 pm.start_servers = 15 pm.min_spare_servers = 15 pm.max_spare_servers = 25
Dacă ați dezvoltat PHP în ultimii ani, probabil că sunteți conștient de problemele limbajului. Veți auzi adesea că este un limbaj fragmentat, un instrument de hacking, că nu are specificații reale etc. Realitatea este că PHP a crescut foarte mult în ultima vreme. PHP 5.4 l-a adus mai aproape de un model de obiect complet și a introdus o mulțime de funcționalități noi.
Și toate acestea sunt bune, desigur, dar cum rămâne cu cadrele? Există un număr mare de ele în PHP. Odată ce începi să cauți, îți vei da seama că nu vei avea suficient timp să le studiezi pe toate, pentru că noi cadre apar constant și se inventează ceva diferit în fiecare. Deci, cum transformi acest lucru în ceva care nu înstrăinează dezvoltatorii și care permite portarea funcționalității cu ușurință de la un cadru la altul?
Ce este PHP-FIG
PHP-FIG (PHP Framework Interop Group) este un grup organizat de dezvoltatori al cărui scop este să găsească modalități prin care mai multe cadre să funcționeze împreună.
Imaginează-ți: în prezent susții un proiect Zend Framework care are nevoie de un modul de coș de magazin. Ai scris deja un astfel de modul pentru un proiect anterior, care era pe Symphony. De ce să nu o mai faci? Din fericire, atât ZendF, cât și Symphony fac parte din PHP-FIG, așa că este posibil să importați un modul dintr-un cadru în altul. Nu e grozav?
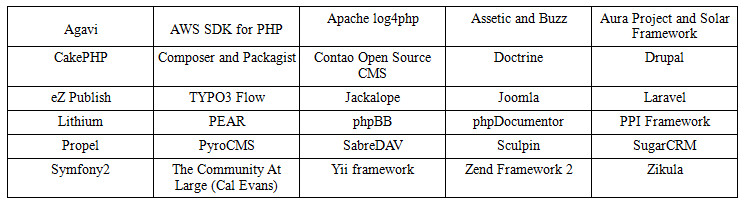
Să aflăm ce cadre sunt incluse în PHP-FIG
Membri PHP-FIG
Orice dezvoltator își poate adăuga cadrul pe lista participanților PHP-FIG. Cu toate acestea, va trebui să plătiți niște bani pentru a face acest lucru, așa că, dacă nu aveți sprijinul comunității, este puțin probabil să fiți de acord cu asta. Acest lucru se face pentru a preveni înregistrarea a milioane de microframework fără nicio reputație.
Membrii actuali:
Ce este PSR?
PSR (PHP Standards Recommendations) - recomandări standard, rezultat al muncii PHP-FIG. Unii membri ai Grupului propun reguli pentru fiecare PSR, în timp ce alții votează pentru susținerea sau eliminarea regulilor. Discuția are loc în Grupuri Google, iar seturile PSR sunt disponibile pe site-ul web oficial PHP-FIG.
Să ne uităm la câteva PSR-uri:
Primul pas către unificarea cadrelor este acela de a avea o structură comună de directoare, motiv pentru care a fost adoptat un standard comun de pornire.
- Spațiul de nume și clasa trebuie să aibă structura \\(\)*.
- Fiecare spațiu de nume trebuie să conțină un spațiu de nivel superior („Numele furnizorului”).
- Fiecare spațiu de nume poate avea câte niveluri se dorește.
- Fiecare separator de spațiu de nume este convertit în DIRECTORY_SEPARATOR când este încărcat.
- Fiecare caracter „_” din CLASS NAME este convertit în DIRECTORY_SEPARATOR.
- Spațiul de nume complet calificat și clasa sunt adăugate cu „.php” atunci când sunt încărcate.
Exemplu de funcție de încărcare automată:

PSR-1 - Standard de codare de bază
Aceste PSR-uri reglementează standardele de bază, ideea principală a cărora este că, dacă toți dezvoltatorii folosesc aceleași standarde, atunci codul poate fi portat fără probleme.
- Fișierele trebuie să utilizeze numai etichete
- Fișierele trebuie să utilizeze numai codificare UTF-8 fără BOM.
- Numele și clasele spațiilor trebuie să urmeze PSR-0.
- Numele claselor trebuie declarate în notația StudlyCaps.
- Constantele clasei trebuie declarate cu litere mari, separate prin liniuțe de subliniere.
- Metodele trebuie declarate în notație camelCase.
PSR-2 - Ghid de stil de codare
Acestea sunt instrucțiuni extinse pentru PSR-1 care descriu regulile de formatare a codului.
- Codul trebuie să respecte PSR-1.
- Ar trebui folosite 4 spații în loc de file.
- Nu ar trebui să existe o limită strictă a lungimii liniilor; lungimea recomandată este de până la 80 de caractere.
- Ar trebui să existe o linie goală după declarația spațiului de nume.
- Parantezele pentru clase ar trebui să se deschidă pe linia următoare după declarație și să se închidă după corpul clasei (la fel pentru metode).
- Trebuie definită vizibilitatea metodelor și proprietăților (publice, private).
- Parantezele de deschidere pentru structurile de control trebuie să fie pe aceeași linie, parantezele de închidere trebuie să fie pe linia următoare după corpul structurii.
- Spațiile nu sunt plasate după parantezele de deschidere ale metodelor structurii de control și înainte de parantezele de închidere.
PCR-3 - Interfață de înregistrare
PCR-3 reglementează înregistrarea, în special cele nouă metode principale.
- LoggerInterface oferă 8 metode pentru înregistrarea a opt niveluri RFC 5424 (depanare, notificare, avertizare, eroare, critică, alertă, urgență).
- A noua metodă log() ia nivelul de avertizare ca prim parametru. Apelarea unei metode cu un parametru de nivel de alertă trebuie să returneze același rezultat ca și apelarea unei metode la un anumit nivel de jurnal (log(ALERT) == alert()). Apelarea unei metode cu un nivel de avertizare nedefinit trebuie să arunce o excepție Psr\Log\InvalidArgumentException.
La fel ca PSR-0, PSR-4 oferă metode îmbunătățite de încărcare automată
- Termenul „clasă” se referă la clase, interfețe, trăsături și alte structuri similare
- Numele de clasă complet calificat are următoarea formă: \
(\ )*\ - Când încărcați un fișier care se potrivește cu un nume de clasă complet calificat:
- O serie învecinată de unul sau mai multe spații de nume principale, fără a număra delimitatorul de spațiu de nume principal, într-un nume de clasă complet calificat corespunde cel puțin unui „director rădăcină”.
- Numele directoarelor și subdirectoarelor trebuie să se potrivească cu majuscule și minuscule ale spațiului de nume.
- Sfârșitul numelui complet al clasei corespunde cu numele fișierului care se termină în .php. Lipsa numelui fișierului trebuie să se potrivească cu majusculele sfârșitului numelui complet al clasei.
- O implementare de încărcare automată nu trebuie să arunce excepții, să genereze erori de orice nivel și nu trebuie să returneze o valoare.
Concluzie
PHP-FIG schimbă modul în care sunt scrise cadrele, dar nu și modul în care funcționează. Clienții solicită adesea să lucrați cu codul existent într-un cadru sau să determinați cu ce cadru ar trebui să lucrați la un proiect. Recomandările PSR fac viața mult mai ușoară dezvoltatorilor în acest sens și asta e grozav!
1. GROUP BY o tastă
Această funcție funcționează ca GROUP BY pentru matrice, dar cu o limitare importantă: este posibilă o singură „coloană” de grupare ($identificator).
Funcția arrayUniqueByIdentifier(array $array, șir $identificator) ( $ids = array_column($array, $identifier); $ids = array_unique($ids); $array = array_filter($array, function ($key, $value); ) folosește ($ids) ( return in_array($value, array_keys($ids)); ), ARRAY_FILTER_USE_BOTH); return $array; )
2. Detectarea rândurilor unice pentru un tabel (matrice bidimensională)
Această funcție este pentru filtrarea „rândurilor”. Dacă spunem că o matrice bidimensională este un tabel, atunci fiecare element al său este un rând. Deci, putem elimina rândurile duplicate cu această funcție. Două rânduri (elementele primei dimensiuni) sunt egale, dacă toate coloanele lor (elementele celei de-a doua dimensiuni) sunt egale. Pentru compararea valorilor „coloană” se aplică: Dacă o valoare este de tip simplu, valoarea în sine va fi utilizată la comparare; în caz contrar, va fi folosit tipul său (matrice, obiect, resursă, tip necunoscut).
Strategia este simplă: faceți din tabloul original un tablou superficial, în care elementele sunt implodate d „coloane” ale matricei originale; apoi aplicați array_unique(...) pe el; și ca ultima utilizare a ID-urilor detectate pentru filtrarea matricei originale.
Funcția arrayUniqueByRow(array $table = , șir $implodeSeparator) ( $elementStrings = ; foreach ($table as $row) ( // Pentru a evita notificări precum „Conversia matrice în șir”. $elementPreparedForImplode = array_map(funcție ($câmp) ( $valueType = gettype($field); $simpleTypes = ["boolean", "integer", "double", "float", "string", "NULL"]; $field = in_array($valueType, $simpleTypes)? $câmp: $valueType; returnează $câmp; ), $rând); returnează $tabel; )
De asemenea, este posibil să îmbunătățiți compararea, detectând clasa valorii „coloană”, dacă tipul acesteia este obiect.
$implodeSeparator ar trebui să fie mai mult sau mai puțin complex, z.B. spl_object_hash($this) .
3. Detectarea rândurilor cu coloane de identificare unică pentru un tabel (matrice bidimensională)
Această soluție se bazează pe a 2-a. Acum „rândul” complet nu trebuie să fie unic. Două „rânduri” (elementele primei dimensiuni) sunt acum egale, dacă toate relevante„câmpurile” (elementele celei de-a doua dimensiuni) ale unui „rând” sunt egale cu „câmpurile” corespunzătoare (elementele cu aceeași cheie).
„Câmpurile” „relevante” sunt „câmpurile” (elementele celei de-a doua dimensiuni), care au cheie, care este egală cu unul dintre elementele „identificatorilor” transmise.
Funcția arrayUniqueByMultipleIdentifiers(array $tabel, matrice $identificatori, șir $implodeSeparator = null) ( $arrayForMakingUniqueByRow = $removeArrayColumns($table, $identifiers, true); $arrayUniqueByRow = $arrayUniqueByRow, $MarrayUniqueByRow, $MarrayMakingUniqueByRow; tipleI identificatori = array_intersect_key ($table, $arrayUniqueByRow); return $arrayUniqueByMultipleIdentifiers; ) funcția removeArrayColumns(array $table, array $columnNames, bool $isWhitelist = false) ( foreach ($table as $rowKey => $row) (dacă $ (este) rând )) ( dacă ($isWhitelist) ( foreach ($row ca $fieldName => $fieldValue) ( dacă (!in_array($fieldName, $columnNames))) ( unset($table[$rowKey][$fieldName]) ); ) ) ) else ( foreach ($rând ca $fieldName => $fieldValue) ( dacă (în_array($fieldName, $columnNames))) ( unset($table[$rowKey][$fieldName]); ) ) ) ) returnează tabelul $; )
De când dezvoltarea tehnologiei a dus la faptul că fiecare programator are acum propriul computer, ca efect secundar avem mii de biblioteci diferite, cadre, servicii, API-uri etc. pentru toate ocaziile. Dar când vine acest caz al vieții, apare o problemă - ce să folosești și ce să faci dacă nu prea se potrivește - rescrie-l, scrie-l pe al tău de la zero sau atașează mai multe soluții pentru diferite cazuri de utilizare.
Cred că mulți oameni au observat că de multe ori crearea unui proiect se reduce nu atât la programare, cât la scrierea de cod pentru integrarea mai multor soluții gata făcute. Uneori, astfel de combinații se transformă în soluții noi care pot fi folosite în mod repetat în problemele ulterioare.
Să trecem la o anumită sarcină „de rulare” - un strat de obiect pentru lucrul cu baze de date în PHP. Există o mare varietate de soluții, de la PDO la motoarele ORM cu mai multe niveluri (și, după părerea mea, nu sunt complet adecvate în PHP).
Majoritatea acestor soluții au migrat la PHP de pe alte platforme. Dar de multe ori autorii nu țin cont de caracteristicile PHP, ceea ce ar simplifica foarte mult atât scrierea, cât și utilizarea constructelor portate.
Una dintre arhitecturile comune pentru această clasă de sarcini este modelul Active Record. În special, acest șablon este folosit pentru a construi așa-numitele Entități, care sunt utilizate într-o formă sau alta într-o serie de platforme, variind de la fasole persistente în EJB3 la EF în .NET.
Deci, să construim o construcție similară pentru PHP. Să combinăm două lucruri interesante - biblioteca ADODB gata făcută și proprietățile slab tastate și dinamice ale obiectelor limbaj PHP.
Una dintre numeroasele caracteristici ale ADODB este așa-numita generare automată de interogări SQL pentru inserarea (INSERT) și actualizarea (UPDATE) înregistrărilor bazate pe tablouri asociative cu date.
De fapt, nu există nimic militar pentru a lua o matrice, unde cheile sunt numele câmpurilor, iar valorile sunt, respectiv, datele și generează un șir de interogare SQL. Dar ADODB o face într-un mod mai inteligent. Interogarea se bazează pe structura tabelului, care este citită anterior din schema bazei de date. Ca rezultat, în primul rând, numai câmpurile existente sunt incluse în sql și nu totul într-un rând, în al doilea rând, se ia în considerare tipul câmpului - se adaugă ghilimele pentru șiruri, formatele de dată pot fi formate pe baza mărcii de timp dacă ADODB îl vede în loc de un șir în valoarea transmisă etc.
Acum să trecem din partea PHP.
Să ne imaginăm o astfel de clasă (simplificată).
Entitate de clasă (protejat $fields = array(); funcția finală publică __set($name, $value) ( $this->fields[$name] = $value; ) public final function __get($name) ( return $ aceasta- >câmpuri[$nume]; ) )
Trecând matricea internă bibliotecii ADODB, putem genera automat interogări SQL pentru a actualiza o înregistrare în baza de date cu un anumit obiect. În același timp, nu este nevoie de proiecte greoaie pentru maparea câmpurilor din tabelul bazei de date la o entitate bazată pe XML câmpuri obiect și altele asemenea. Este necesar doar ca numele câmpului să se potrivească cu proprietatea obiectului. Deoarece modul în care sunt numite câmpurile din baza de date și câmpurile obiectului nu contează pentru computer, nu există niciun motiv pentru care acestea să nu se potrivească.
Să arătăm cum funcționează în versiunea finală.
Codul pentru clasa finalizată se află pe Gist. Aceasta este o clasă abstractă care conține minimul necesar pentru a lucra cu baza de date. Observ că această clasă este o versiune simplificată a unei soluții care a fost testată pe câteva zeci de proiecte.
Să ne imaginăm că avem un semn ca acesta:
CREATE TABLE `users` (`username` varchar(255) , data `created` , `user_id` int(11) NOT NULL AUTO_INCREMENT, PRIMARY KEY (`user_id`))
Tipul bazei de date nu contează - ADODB oferă portabilitate la toate serverele de baze de date comune.
Să creăm o clasă de entitate User pe baza clasei de entitate
/** * @table=users * @keyfield=user_id */ class Utilizatorul extinde Entity( )
Asta e tot.
Ușor de folosit:
$utilizator = utilizator nou(); $user->username="Vasya Pupkin"; $user->created=time(); $utilizator->salvare(); //salvare în stocare //încărcare din nou $thesameuser = User::load($user->user_id); echo $thesameuser ->nume utilizator;
Indicăm tabelul și câmpul cheie în pseudo-adnotări.
De asemenea, putem specifica o vizualizare (de exemplu, view =usersview) dacă, așa cum este adesea cazul, entitatea este selectată pe baza tabelului său cu câmpuri atașate sau calculate. În acest caz, datele vor fi selectate din vizualizare și tabelul va fi actualizat. Cei cărora nu le plac astfel de adnotări pot suprascrie metoda getMetatada() și pot specifica parametrii tabelului în tabloul returnat.
Ce altceva este util despre clasa Entity în această implementare?
De exemplu, putem suprascrie metoda init(), care este apelată după ce este creată o instanță Entity, pentru a inițializa data implicită de creare.
Sau supraîncărcați metoda afterLoad(), care este apelată automat după încărcarea unei entități din baza de date, pentru a converti data într-un marcaj de timp pentru o utilizare mai convenabilă.
Ca rezultat, obținem o structură nu mult mai complexă.
/** * @table=users * @view=usersview * @keyfield=user_id */ class Utilizatorul extinde Entity( protected function init() ( $this->created = time(); ) protected function afterLoad() ( $this ->created = strtotime($this->created); ) )
De asemenea, puteți supraîncărca metodele beforeSave și beforeDelete și alte evenimente ale ciclului de viață în care puteți, de exemplu, efectua validarea înainte de a salva sau alte acțiuni - de exemplu, eliminați imagini din încărcare atunci când ștergeți un utilizator.
Încărcăm o listă de entități după criteriu (în esență o condiție pentru UNDE).
$users = Utilizator::load("nume de utilizator ca "Pupkin" ");
De asemenea, clasa Entity vă permite să executați o interogare SQL arbitrară, „nativă”, ca să spunem așa. De exemplu, dorim să returnăm o listă de utilizatori cu unele grupări bazate pe statistici. Nu contează ce câmpuri specifice vor fi returnate (principalul este că ar trebui să existe un user_id dacă este nevoie de o manipulare suplimentară a entității), trebuie doar să le cunoașteți numele pentru a accesa câmpurile selectate. Când salvați o entitate, așa cum este evident din cele de mai sus, nu trebuie să completați toate câmpurile care vor fi prezente în obiectul entitate, acestea vor merge în baza de date. Adică, nu trebuie să creăm clase suplimentare pentru mostre aleatorii. La fel ca structurile anonime la preluarea în EF, doar că aici este aceeași clasă de entitate cu toate metodele logicii de afaceri.
Strict vorbind, metodele de mai sus pentru obținerea listelor sunt oarecum dincolo de modelul AR. În esență, acestea sunt metode din fabrică. Dar, așa cum a lăsat moștenire bătrânul lui Occam, să nu creăm entități dincolo de ceea ce este necesar și să creăm un Entity Manager separat sau ceva de genul acesta.
Rețineți că cele de mai sus sunt doar clase PHP și pot fi extinse și modificate după cum doriți, adăugând proprietăți și metode logice de afaceri la entitate (sau la clasa de bază Entity). Adică, primim nu doar o copie a unui rând de tabel al bazei de date, ci și o entitate de afaceri ca parte a arhitecturii obiect a aplicației.
Cine ar putea beneficia de asta? Desigur, nu pentru dezvoltatorii experimentați care cred că folosirea a ceva mai simplu decât o doctrină nu este respectabilă și nu pentru perfecționiștii care sunt încrezători că, dacă o soluție nu scoate un miliard de apeluri către baza de date pe secundă, atunci nu este o soluție. . Judecând după forumuri, mulți dezvoltatori obișnuiți care lucrează la proiecte obișnuite (99,9%) se confruntă mai devreme sau mai târziu cu problema găsirii unui mod simplu și convenabil bazat pe obiecte de a accesa baza de date. Dar ei se confruntă cu faptul că majoritatea soluțiilor sunt fie nerezonabil de sofisticate, fie fac parte dintr-un fel de cadru.
P.S. Am realizat soluția din cadru ca proiect separat
limbaj de programare PHP a parcurs un drum lung de la un instrument pentru crearea de pagini personale la un limbaj de uz general. Astăzi este instalat pe milioane de servere din întreaga lume, folosit de milioane de dezvoltatori care creează o mare varietate de proiecte.
Este ușor de învățat și extrem de popular, mai ales printre începători. Prin urmare, dezvoltarea limbii a fost urmată de o dezvoltare puternică a comunității din jurul acesteia. Un număr mare de scripturi, pentru toate ocaziile, biblioteci diferite, cadre. Lipsa standardelor uniforme pentru proiectarea și scrierea codului a dus la apariția unui strat uriaș de produse informaționale construite pe principiile proprii ale dezvoltatorului acestui produs. Acest lucru a fost vizibil mai ales atunci când lucrați cu diverse cadre PHP, care a reprezentat multă vreme un ecosistem închis, incompatibil cu alte cadre, în ciuda faptului că sarcinile pe care le rezolvă sunt adesea asemănătoare.
În 2009, dezvoltatorii mai multor cadre au fost de acord să creeze o comunitate PHP Framework Interop Group (PHP-FIG), care ar dezvolta recomandări pentru dezvoltatori. Este important să subliniem că nu este vorba despre asta Standardele ISO, este mai corect să vorbim despre recomandări. Dar din moment ce cei care au creat PHP-FIG Deoarece comunitatea de dezvoltatori reprezintă cadre mari, recomandările lor au o greutate serioasă. A sustine Standarde PSR (recomandare standard PHP). permite compatibilitatea, ceea ce facilitează și accelerează dezvoltarea produsului final.
În total, la momentul scrierii, există 17 standarde, 9 dintre ele sunt aprobate, 8 sunt în faza de proiect, discutate activ, 1 standard nu este recomandat pentru utilizare.
Acum să trecem direct la descrierea fiecărui standard. Vă rugăm să rețineți că nu voi intra în detaliu despre fiecare standard aici, mai degrabă aceasta este o scurtă introducere. De asemenea, articolul le va lua în considerare doar pe acestea Standardele PSR, care sunt acceptate oficial, adică sunt în starea Acceptat.
PSR-1. Standard de codare de bază
Reprezintă cele mai generale reguli, cum ar fi utilizarea Etichete PHP, codificarea fișierelor, separarea locului de declarare a funcției, clasa și locul utilizării acestora, denumirea claselor și metodelor.
PSR-2. Ghid de stil de cod
Este o continuare a primului standard și reglementează utilizarea filelor și a întreruperilor de linie în cod, lungimea maximă a liniilor de cod, regulile de proiectare a structurilor de control etc.
PSR-3. Interfață de înregistrare.
Acest standard este conceput pentru a permite (înregistrarea) logarea în aplicațiile în care sunt scrise PHP.
PSR-4. Standard de pornire
Acesta este probabil cel mai important și necesar standard, care va fi discutat într-un articol separat, detaliat. Clase care implementează PSR-4, poate fi încărcat de un singur autoloader, permițând pieselor și componentelor dintr-un cadru sau bibliotecă să fie folosite în alte proiecte.
PSR-6. Interfață de stocare în cache
Memorarea în cache este utilizată pentru a îmbunătăți performanța sistemului. ȘI PSR-6 vă permite să stocați și să preluați în mod standard date din cache folosind o interfață unificată.
PSR-7. Interfață de mesaje HTTP
Când scrieți mai mult sau mai puțin complex site-uri web în PHP, aproape întotdeauna trebuie să lucrezi cu Antete HTTP. Cu siguranță, limbaj PHP ne oferă opțiuni gata făcute pentru a lucra cu ei, cum ar fi matrice superglobală $_SERVER, funcții antet(), setcookie() etc., cu toate acestea, analiza lor manuală este plină de erori și nu este întotdeauna posibil să se țină cont de toate nuanțele lucrului cu ele. Și astfel, pentru a ușura munca dezvoltatorului, precum și pentru a face interfața pentru a interacționa cu Protocolul HTTP acest standard a fost adoptat. Voi vorbi mai detaliat despre acest standard într-unul din articolele următoare.
PSR-11. Interfață container
Când scriu programe PHP De multe ori trebuie să utilizați componente terțe. Și pentru a nu ne pierde în această pădure de dependențe, au fost inventate diverse metode de gestionare a dependențelor de cod, adesea incompatibile între ele, pe care acest standard le aduce la un numitor comun.
PSR-13. Link-uri hipermedia
Această interfață este concepută pentru a facilita dezvoltarea și utilizarea interfețelor de programare a aplicațiilor ( API).
PSR-14. Interfață simplă de stocare în cache
Este o continuare și îmbunătățire a standardului PSR-6
Astfel, astăzi ne-am uitat Standardele PSR. Pentru informații actualizate cu privire la stadiul standardelor, vă rugăm să contactați: