Что такое Яндекс XML? Это сервис Яндекса, позволяющий отправлять определённое количество запросов к поиску Яндекса без риска получить бан, и, соответственно, без капчи. Вот зачем нужен XML. Сделано это было, чтобы как-то контролировать неугомонных вебмастеров, нагружавших сервера Яндекса отправлением бесчисленных запросов. Чтобы попасть в свои настройки XML, надо пройти по адресу https://xml.yandex.ru . Прежде всего следует убедиться, что XML лимиты у вас есть. Они должны либо даваться к сайтам, которые есть у вас в Вебмастере, либо их можно купить, о чем позже. Как только вы добавляете сайт в Яндекс Вебмастер, у вас появляются лимиты. Их наличие видно во вкладке «Лимиты».
У меня, допустим, сейчас такое количество лимитов. Они есть, значит снова идём в настройки https://xml.yandex.ru/settings/, указываем свой IP в поле «Основной IP-адрес» (обычно он совпадает с указанным в «Ваш текущий IP»), ставим галочку «Я принимаю условия лицензионного соглашения», жмём «Сохранить». В итоге там же вверху появится «URL для запросов», который нужно будет указывать в софте, через который снимаются позиции.

Что вообще за формат XML
XML — это формат, в котором сервис Яндекса возвращает результаты на XML-запросы. Иначе говоря, расширяемый язык разметки, о котором можно прочесть на Википедии. Но вам, если вы занимаетесь продвижением сайтов, о нем следует знать лишь то, что этот формат годен и для обработки документов программами, и для предоставления информации в читаемой человеком форме, поэтому Яндекс его и использует.
Что такое XML лимиты Яндекса
Что значит один лимит Яндекс XML? Он значит, что по одному лимиту вы можете сделать одно обращение к поисковой системе без капчи. Если у вас есть 500 лимитов, то вы сможете снимать позиции по 500 запросам в день. Один лимит - один запрос. Но тут есть нюансы - например, ограничение на использование лимитов в час. То есть эти ваши 500 запросов распределяются по 24 часам, и вы не можете моментально снять эти 500 позиций. Днём ограничение жестче, поэтому многие оптимизаторы снимают позиции ночью. Вот пример:

И еще такой момент - если на вашем IP уже пользуются одним аккаунтом Яндекса для совершения обращений к XML, то воспользоваться вторым не удастся. Один IP - один URL для запросов.
До конца неясно, по какому принципу Яндекс высчитывает, какое количество лимитов следует предоставить тому или иному сайту. Многие считают, что формула для расчета количества лимитов как-то связана с расчетом трастовости сайта.
Есть ещё несколько важных моментов:
- их количество регулярно обновляется;
- использование ограничивается в определенное время суток (ночью – самое высокое количество);
- лимиты можно передавать и продавать (об этом ниже).
Зачем Яндексу нужен этот сервис
Собственно, из истории создания сервиса понятно, зачем он нужен Яндексу. Благодаря XML-лимитам, Яндекс сам регулирует нагрузку на свои сервера. Именно поэтому максимальное количество запросов можно использовать ночью, а минимальное – в рабочие часы.
Сильно ли XML выдача отличается от реальной
Да, отличия есть довольно существенные. Очень многие сеошники и вебмастера лично мне жаловались, что в выдаче место одно, а в XML — другое (для тех, кто сейчас подумал, что я общаюсь с дураками — нет, персонализация у них включена не была и вообще они смотрели с Tor или режима инкогнито в Chrome). И топ-10 тоже отличается. Но на больших объемах это заметно не очень сильно.
Если для вас очень важно качество, то лучше ориентироваться на выдачу. А если количество (которое, конечно, по закону диалектики переходит в качество) — то XML лимиты упростят задачу.
Как пользоваться лимитами
Выше я уже говорил, что для использования сервиса нам нужен урл для запросов. Его надо копировать и вставлять в какую-либо программу или онлайн-сервис, который будет делать обращения к вашему урлу.
Majento PositionMeter
Скачать программу можно . Обновлять лучше всего через «Помощь - Обновления - Обновить версию», то есть не надо скачивать ее с сайта и устанавливать заново поверх существующей.
Сначала заходим в «Сайты - Настройки». Время между запросами Яндекс и Гугл - это нам не понадобится, поскольку снимать будем через XML, но пусть будет 3000 мс. Можно снять галочку с «Проверять позиции при добавлении новых запросов», а вот «Автосохранение данных каждые 15 минут» можно поставить.
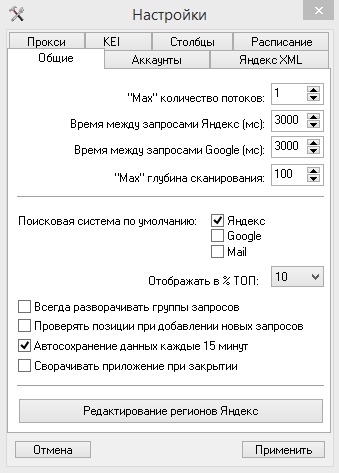
Вкладка «Столбцы» - двойной щелчок левой кнопкой мыши, чтобы убрать пункт. Можно убрать «Худшая позиция».

А теперь собственно то, ради чего мы здесь собрались. Указываем во вкладке «Яндекс XML» URL для совершения запросов, который выводился у нас в интерфейсе сервиса. Просто копируем и вставляем сюда.

Добавляем новый сайт зелёным плюсом и указываем запросы для него, а потом регион. Потом жмём «Сохранить всё» и сохраняем файл в папку Majento. В «Настроить поиск» можно поставить галочку «учитывать поддомены».
Можно создавать группы и переносить туда сайты. Например:
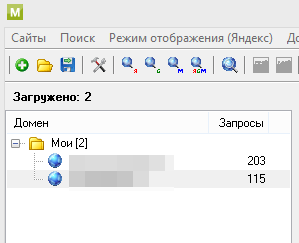
К каждому запросу можно добавить комментарий, щелкнув на нём правой кнопкой мыши и нажав «Изменить комментарий к запросу». Можно получить пропущенные посадочные URL. Если нажать правой кнопкой мыши на запросах, то будет пункт «графики и аналитика», с его помощью можно посмотреть общую динамику запросов.
В «Дополнениях» можно проверить список URL на индексацию, а также проверить обратные ссылки.
Key Collector
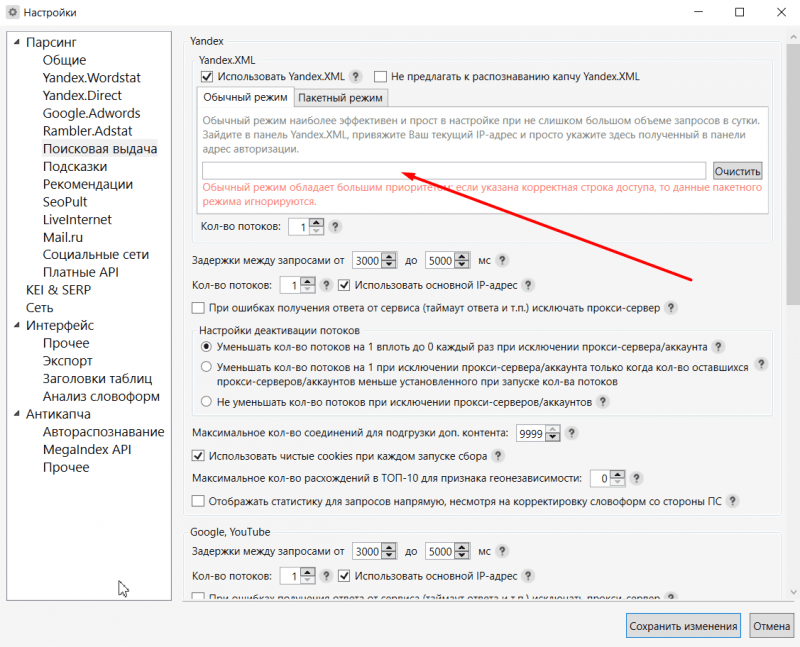
В настройках ставим галочку «Использовать Yandex.XML». Вводим в текстовое поле специальный УРЛ. Выставляем количество потоков от 5 до 10, это ускорит проверку в соответствующее количество раз.
Топвизор
В этом сервисе есть возможность передать им свои лимиты Яндекс, после чего часть из них будет доступна для съема позиций в . Если не нравятся десктопные программы или не хочется хранить проекты на своей машине, то это решение будет самым лучшим.

Как передать XML лимиты
Нужно скопировать урл для запросов, как я уже упоминал выше, и вставить его в соответствующих настройках сервиса или программы, которыми хотите пользоваться.
Примеры практического применения лимитов
Самое очевидное, для чего нужен XML Яндекса — это съем позиций по запросам. То есть вы можете отслеживать позиции своих страниц по запросам и добивать их до топ-3, допустим.
Вот отличное видео Бакалова о том, как можно с помощью Яндекс XML определить витальные запросы:
Еще один вариант — это съем релевантных страниц вашего сайта по запросам в Яндексе.
Где можно купить XML лимиты Яндекса
Продажа и покупка лимитов совершенно не запрещена. Александр Садовский лично дал добро. Можно покупать и продавать их напрямую — например, делегировать лимиты на кого-то из знакомых в обмен на бабло. А можно использовать биржи. Хоть они и берут комиссию, но обычно через них нет проблем продать лимиты.
Лучшее решение — XMLproxy
Я для себя решил, что удобнее всего работать с . Там вы покупаете лимиты не пакетами, а поштучно. Стоимость одного запроса составляет 0.005р. То есть смотрите - если вы не пользуетесь XML ежедневно, а, допустим, раз в неделю совершаете 800 запросов, то в месяц вы заплатите 16 рублей в XMLproxy, а в XMLStock например отдали бы сотню. При этом вы бы не могли совершать больше 1000 запросов в сутки, а тут такого ограничения нет - плата идёт за запрос, а не за пакет. Если же вы совершаете 800 запросов каждый день, то в XMLproxy получается уже 120 рублей против 100 рублей в месяц по XMLStock.
Другие биржи
Наиболее крупная и старая биржа лимитов. Лимиты покупаются пакетами. То есть вы можете, допустим, взять пакет на 1000 лимитов и будете платить за неё 100 рублей в месяц. И каждый день в течение этого месяца сможете совершать 1000 запросов.
Majento - XML лимиты Яндекса можно покупать и через Majento, там тоже пакетами по сотне за косарь лимитов.
Просто ещё один вариант на крайняк.
Как продать лимиты и какой с этого профит
Скажу сразу, что заработок с таких продаж небольшой, но вполне хватит, допустим, на оплату домена.
Я делегирую XMLproxy около 3500 лимитов, и за год у меня накапало что-то около 800 рублей. Копейки конечно, но копейка-то рубль бережет.
Я думаю, что Вы уже представляете себе, зачем нужен HTML (да, HTML ). Он нужен для представления данных в браузере. То есть имеется HTML-код и соответствующий этому HTML-коду определённый вид. Однако, современные тенденции требуют не просто отображения данных, но ещё и их грамотной внутренней структуры.
Вот именно для создания структуры и существует язык XML . Простой пример:
Зелёное яблоко
Для нас людей сразу всё становится понятно. В голове возникает сразу образ "зелёного яблока ", однако, как объяснить компьютеру, что это яблоко, а не апельсин, человек или наша галактика? Здесь вновь приходит на помощь XML , где мы можем создавать любые теги, давая чётко понять, где яблоко, где апельсин, где человек, а где наша галактика. Надеюсь, понятно объяснил.
Теперь о самом главном. Главная особенность XML - это его универсальность . То есть XML понимает любой современный язык. А так как XML - это текстовый файл , то с ним можно работать и в обычном блокноте. Теперь конкретно к практике, где используется XML :
- Файл-настроек . Настройки в XML-файле очень легко считывать и записывать. По этой причине на Вашем компьютере находятся сотни XML-файлов .
- Мост для обмена данными между программами, написанными на разных языках. Очень важная особенность, следующая из универсальности языка, и это регулярно используется в сложных системах.
- Хранение данных . Фактически, это некий аналог базы данных, но не требующий СУБД (например, MySQL ). А благодаря языку запросов XPath становится возможным легко общаться с этой "базой данных ".
И, наконец, из своей практики могу привести самый простой пример. У меня на сайте есть карта сайта в формате XML . Там находятся ссылки на все страницы сайта. Это вещь весьма удобная и важная для хорошей индексации сайта, однако, каждый раз вручную добавлять туда новую страницу неудобно. Поэтому благодаря знаниям по работе с XML , я это дело легко автоматизировал. Так что XML - полезный язык , который надо знать любому программисту хотя бы в общих чертах.
XML используется во многих аспектах веб-разработки, но основная его задача - облегчение хранения и передачи данных.
XML отделяет данные от HTML
Если вам в HTML документе необходимо отображать динамические данные, то это будет занимать слишком много времени, если всякий раз, когда эти данные изменились, редактировать сам HTML документ.
С XML данные можно хранить в отдельных файлах XML. При этом вы сосредотачиваетесь на использовании HTML/CSS для отображения и шаблонизации и можете быть уверены, что поступающие новые данные не потребуют каких-либо изменений в коде HTML документа.
XML упрощает распределение данных
В реальном мире компьютерные системы и базы данных используют данные в несовместимых форматах.
XML данные хранятся в простом текстовом формате. Это обеспечивает программную и аппаратную независимость.
Это позволяет легко создавать данные, которые могут использоваться самыми разными приложениями.
XML упрощает передачу данных
Одной из самых время затратных проблем разработчиков всегда была и остается до сих пор проблема обмена данными между несовместимыми между собой системами.
Передача данных в виде XML значительно снижает сложность этой проблемы, так как данные в этом формате могут быть прочитаны разными несовместимыми приложениями.
XML упрощает модификацию платформы
Переход на новые системы (аппаратные или программные платформы) всегда занимает много времени. Множество данных необходимо конвертировать в новые форматы. При этом часто несовместимые данные теряются.
XML данные хранятся в текстовом формате. Это значительно облегчает расширение или модернизацию операционных систем, переход на новые приложения или браузеры без опасности потерять данные.
XML делает ваши данные более доступными
Доступ к вашим данным могут получать не только HTML документы, но и любые другие приложения.
Благодаря XML ваши данные становятся доступными для всех видов "машин чтения" (голосовых машин, новостных каналов и т.д.), что позволяет значительно проще обращаться к ним людям с ограничениями по зрению и другими физическими проблемами.
XML используется для создания новых интернет-языков
С использованием XML было создано множество языков программирования в Интернете.
Вот несколько примеров:
- XHTML
- WSDL для описания доступных веб-сервисов
- WAP и WML как языки разметки для портативных устройств типа КПК
- RSS языки для новостных каналов
- RDF и OWL для описания ресурсов и онтологии
- SMIL для описания мультимедиа для сети
[В последнее время, в связи с появлением этих
страничек, самым частым
вопросом ко мне оказался такой: "Расскажи, а
зачем он вообще нужен, XML?
Разве нам мало HTML? " Не имея многого
времени (или ума;) на изготовление собственных публикаций, а также
глубоко чтя классиков, я предпочел лучше бегло перевести отличную статью
по названной subj
- возможно, это первый эпизод сериала "в помощь" ]
Jon Bosak, Tim Bray
XML and the
Second-Generation Web
из журнала "Scientific
American", май 1999
Дайте людям пару наводок, остальное они сообразят сами. Посмотрев на страницу, где более крупные блоки текста делятся на более мелкие, все быстро понимают, что перед ними начало статьи. Посмотрев на список бакалейных товаров, можно быстро догадаться, что это "инструкция" на посещение магазина. Увидев колонки цифр - понять, что это банковский счет. Компьютеры пока еще не так умны - до них все это приходится доносить точно - с чем конкретно они должны иметь дело и что для этого от них требуется.
Именно для этого - сделать информацию само-описанной - и был придуман новый язык разметки документов - Extensible Markup Language (XML). Эти легко выговариваемые изменения ("само-описанный" документ, смена правил общения с компьютерами) несут в себе огромный потенциал - роль Internet от среды доставки информации начинает расширяться на другие виды человеческой деятельности. И действительно, с момента утверждения ее W3C в 1998г, XML-спецификация со скоростью лесного пожара стала проникать повсюду - в промышленность и науку, в производство товаров и медицину.
Энтузиасты надеялись, что XML даст возможность решить ряд глобальных проблем Web. Проблемы эти известны: во-первых, Internet - суперскоростная сеть, зачастую ведет себя хуже черепахи; а во-вторых, хотя в сети присутствует едва ли не вся информация, найти в ней что-то необходимое нередко бывает до бешенства трудно.
Обе эти проблемы обусловлены, главным образом, природой основного языка Сети - HTML. И хотя успех HTML по сравнению с другими когда-либо предложенными языками электронных публикаций очевиден, HTML слишком скуден: в сущности, он лишь говорит браузеру, как тому разместить на странице текст, картинки и кнопки. HTML упирает на представление информации, и поэтому довольно прост в изучении, однако за это приходится расплачиваться.
Это отражается на сложности разработки web-сайтов, если только эти сайты не должны походить на факсы, рассылающие страницы всем желающим, кто попросит. Более половины людей и компаний во всем мире предпочли бы web-сайты, которые умеют принимать от пользователей заказы, пересылать диагнозы болезней и даже запускать тонкие инструментальные операции в заводских цехах и научных лабораториях. Подобные задачи _НИКОГДА_ не стояли перед HTML!.
К примеру, если даже у вашего врача и получается "извлекать" в свой просмотрщик анализы, взятые из вашей мед.карточки, то вряд ли у него уже получается послать их по сети другому специалисту, чтобы полученный ответ вставить обратно в свою БД. Его компьютер не знает, что делать с информацией, которая ему столь же ясна, как
бе бе бе
илиЛегендарный Керниган однажды заметил, что вся хитрость принципа WYSIWYG (что вижу, то и получаю) состоит в том, что когда ничего не видно, то обычно и получить удается ровно столько же.
Те слова выше, что заключены в угловые скобки, называются тегами. В HTML нет никакого тега для анализов, и отсюда другой его недостаток: негибкость. Добавление в язык нового тега - это такая бюрократическая волокита, столь длительная, что никто с этим и связываться не будет. А ведь свои собственные теги не помешали бы каждой программе, а не только такой, как в приведенном примере с врачом.
Это во многом объясняет сегодняшние медленные темпы создания онлайновых магазинов, каталогов по почте и прочих интерактивных сайтов. Изменив количество единиц заказа и способ доставки, и увидев горсточку поменявшихся в поле "сумма" цифр, вам все равно придется запрашивать удаленный (и без того перегруженный работой) сервер прислать вам обратно полную вновь сформированную страницу с графикой и всем остальным. Тогда как ваш собственный мощный компьютер будет праздно простаивать, потому что только что узнал нечто типа
и
, но не цены с вариантами доставки.Добавьте к этому и
неудовлетворительное качество возможностей поиска в Web. Поскольку не
существует способа как-то особо пометить информацию о ценах, решительно
невозможно осуществлять в web поиск страниц по признаку "цена".
Что-то старое, что-то новое
В принципе, решение
элементарно: в тегах нужно указывать, что это за информация, а не то, как
она должна выглядеть. Например, размечать компоненты заказа на рубашку
тегами "цена, размер, количество, цвет", а не "bold, paragraph, row,
column", как это предлагается в HTML. Тогда программе проще
идентифицировать документ как заказ и выполнить остальную часть работы:
показать этот заказ в том или ином виде, провести через бухгалтерскую
систему, или сделать все так, чтобы назавтра новая рубашка была бы
доставлена к вашему порогу.
Мы, рабочая группа W3C, еще в 1996 г.
приступили к разработке такого проекта. Идея была сильная, хотя и не
совсем оригинальная. На протяжении поколений редакторы и печатники
маркировали рукописные тексты пометками для наборщиков. Подобный "язык
разметки" развивался самостийно до 1986г., пока, в результате десятилетней
работы, Международная Организация по стандартизации (ISO) не ввела систему
создания новых языков разметки.
Получив имя SGML (Standard
Generalized Markup Language), этот язык описания языков - метаязык -
доказал свою полезность на примере многих крупных систем подготовки
публикаций. И даже HTML получил свое определение через SGML. Единственная
трудность с SGML заключалась в его всеядности - там масса заумных вещей
для минимизации нажатий на клавиши, так как в ту пору каждый байт был на
счету. Вот почему сегодня web-браузеры с ним не в ладах.
Создавая
XML, наша рабочая группа очистила SGML от всей шелухи и предложила
строго-целевой и удобоваримый метаязык. Базой XML является набор правил,
руководствуясь которыми, каждый может создать собственный язык разметки.
Эти правила выбраны так, чтобы одна единственная небольшая программа (ее
еще называют парсером или синтаксическим анализатором) могла справиться с
распознаванием любого нового языка. Обратимся снова к примеру с доктором,
который хотел бы передать анализы специалисту. Если бы врачи-профессионалы
выстроили из XML свой язык разметки для кодирования врачебных записей (ряд
групп уже давно работают над проблемой), то в сообщении доктора своему
коллеге могло бы быть нечто вроде
<имя
пациента> blah blah
<аллергия на
лекарство> blah blah blah
В такой постановке уже не сложно
написать программу для произвольно взятого компьютера так, чтобы она могла
распознать эти стандартизованные врачебные записи и умела заносить эту в
прямом смысле жизненно важную информацию в свою базу данных.
Точно
так же, как HTML создавался, чтобы любой пользователь мог читать
Internet-документы, XML дает нам то эсперанто, на котором любой может
читать и писать, невзирая на вавилон несовместимых платформ. Да даже с
точки зрения рядового человека в языке XML больше смысловой нагрузки (в
отличие от других форматов данных), ибо в нем нет чего-то такого, что
выглядело бы нечитабельным текстом.
Мощь универсальности XML
обусловлена минимальным набором правильно выбранных правил. Во-первых -
теги всегда составляют пару, окружая своеобразными скобками текст, к
которому они применяются. Во-вторых - спаренные теги могут вкладываться
друг в друга наподобие кавычек, позволяя выстраивать сложные
многоуровневые структуры.
Правило вкладывания автоматически
обуславливает простоту любого XML-документа, производя структуру,
известную в информатике как дерево. Аналогично генеалогическому дереву,
любой графический или текстовый элемент документа есть отец, сын или брат
(parent, child, sibling) какого-то другого элемента, и это отношение
родства всегда однозначно. Конечно, деревья не описывают все многообразие
структур данных, однако покрывают большую часть типовых случаев применения
компьютеров. Кроме того, деревья необычайно удобны для программистов. Нет
проблем написать небольшой кусочек кода для переупорядочивания транзакций
или вывода на экран вполне понятного чека, когда этот чек представлен в
виде дерева.
Второй источник универсальной силы XML - это опора на
новый стандарт Unicode - систему кодирования, допускающую взаимосмешение
текстов на всех основных языках мира. Напротив, в HTML, как и в массе
текстовых процессоров, документ, как правило, может быть только на одном
конкретном языке, не важно каком - английском, японском или арабском.
А
если программа не знает кодировки какого-то языка, о документе (в HTML)
можно забыть. Бывает и хуже: к примеру, из-за несогласованности кодировок
программы, написанные на Тайване, часто не умеют читать тексты,
ориентированные на материковый Китай. В случае с XML, если программа умеет
правильно с ним работать, она справится с любой комбинацией кодировок.
Таким образом, XML позволяет обмениваться данными не только между разными
компьютерными платформами, но и дает возможность преодолевать национальные
и культурные барьеры.
Конец вселенскому ожиданию (World Wide Wait)
С
распространением XML Сеть должна стать намного "отзывчивее". Сегодня все,
что умеют делать компьютерные устройства в сети, не важно, мощные это
десктопы или карманные органайзеры, это не больше, чем получить форму по
"GET", заполнить ее, потом гонять на web-сервер туда-сюда, пока работа с
формой не будет завершена. XML дает нам возможность передать в форму
структуру и семантику данных, и, следовательно, все эти устройства смогут
делать основную обработку в нужном месте и незамедлительно. Это не только
уменьшит нагрузку на сервера, но и должно привести к существенному
сокращению сетевого трафика.
Для иллюстрации представьте себе, как
в онлайновом бюро путешествий вам нужно подобрать рейс из Лондона в
Нью-Йорк на 4 июля. Скорее всего, вы увидите список в несколько раз
длиннее, чем может поместиться на экране. Этот список можно сократить,
задав более точные параметры типа времени вылета, цены или авиакомпании,
но в этом случае вы просто "нагружаете" сервер бюро путешествий своим
запросом и вынуждены дожидаться ответа. Однако если бы этот длинный список
рейсов вам предоставили в XML, то бюро могло бы сопроводить его небольшим
Java-аплетом, с помощью которого моментально и легко отсортировать и
отсеять ненужное, не прибегая к какому-либо взаимодействию с сервером.
Помножьте это на миллионы пользователей Web, и общий эффект окажется
впечатляющим.
Чем больше сетевой информации будет размечено
"отраслевыми" XML-тегами, тем легче будет найти то, что вы ищете. Сегодня
поиск в Internet по запросу "работа для биржевого брокера" захлестнет вас
лавиной рекламных объявлений, но вероятно, о работе их там будет всего
несколько штук - в основном работа прячется на бесплатных досках
объявлений газетных сайтов, с которыми не любят работать поисковые роботы.
И сейчас Ассоциация Газет Америки (Newspaper Association of America)
создает на XML свой язык разметки объявлений, обещающий сделать процесс
поиска намного эффективнее.
Неважно, пусть это просто промежуточный
шаг. Библиотекари давно знают способы найти что-то быстро - просматривать
не документы, а их компактные ключевые описания, лишь указывающие на сами
источники. А именно, это каталоги с образцом в виде библиотечных карточек.
Подобную информацию об информации и называют "метаданные".
Поэтому
с самого начала важная роль в XML-проекте отводилась созданию
сопутствующего стандарта метаданных. Ту же самую роль, как каталожные
карточки для библиотечных книг, для информации в Web должна сыграть
февральская Спецификация Описаний Ресурсов (Resource Description
Framework, RDF). Распространяясь по Сети, метаданные RDF сделают поиск
намного более быстрым и релевантным, чем сейчас. В Сети нет библиотекарей,
но каждый веб-мастер, ко всему прочему, стремится к легкой "находимости"
его сайта, поэтому мы ожидаем, что RDF, как только людям откроется его
мощь, окажет огромное влияние на развитие Internet.
Разумеется,
информацию можно получать и без поиска. В конце концов, Сеть это
гипертекст - миллиарды страниц, пронизанных гиперссылками - теми
подчеркнутыми словами, по которым достаточно щелкнуть, чтобы умчаться на
какую-то другую страницу. В XML механизм гиперссылок так же многократно
усилен. Спецификация ссылок в XML, называемая XLink и которую W3C готовит
к концу года, даст возможность пользователю выбирать из нескольких адресов
назначения. Еще одна разновидность гиперссылок позволит получать текст или
изображение прямо по месту нажатия, давая возможность посетителю не
покидать страницу.
Вероятно, полезнее всего в XLink окажется та
часть спецификации, которая позволяет авторам прибегать к опосредованным
ссылкам, отсылающим вместо самих страниц в некую сводную БД. Так, если
автор изменил адрес страницы, простым авторским редактированием одной
записи в такой базе данных легко обновить все ссылки, ведущие на его
страницу. Это позволит избавиться от становящихся привычными сообщений
"404 File Not Found", сигнализирующих о "сломавшейся" ссылке.
Сочетание более эффективной обработки, более точного поиска и
более гибкого связывания революционизирует структуру Сети и открывает
совершенно новые методы доступа к информации. Для пользователей эта новая
Сеть станет существенно быстрее, мощнее и полезнее, чем Сеть
сегодняшняя.
Необходимо сотрудничество
Разумеется, не все так просто.
XML позволяет любому сконструировать новый язык на свой лад, однако
создать хороший язык - задача, сложность которой не следует недооценивать.
Придумать язык - лишь самое начало: наивно ожидать, что значения ваших
тегов будут очевидны другим людям, пока вы не снабдили язык руководством,
и будут понятны компьютерам, пока вы не написали программы, работающих с
тегами языка.
Нетрудно объяснить, почему это так. Если бы все
необходимое для того, чтобы научить компьютер обрабатывать заказы,
сводилось к разметке тегами, тогда и XML не понадобился бы. Не нужны были
бы даже программисты - раз компьютеры достаточно умны, чтобы уметь все
делать самостоятельно.
То, зачем нам нужен XML, это не магия, а
результативность. XML устанавливает базовые правила, на один пласт
упрощающие детали программирования - чтобы люди со сходными интересами
могли сконцентрироваться на другом твердом орешке - соглашениях о том, как
именно они хотели бы оформлять данные, которыми им хотят обмениваться. Это
очень непростая проблема, хотя и не новая.
И такие соглашения
будут, поскольку множащаяся несовместимость компьютерных платформ дает нам
в результате задержки сроков, финансовые потери и ведет к неразберихе
почти во всех сферах деятельности. Люди хотят обмениваться идеями и делать
дело, независимо от того, что у всех разные компьютеры - и чтобы это стало
реальностью, взаиморазвитию частных (для разных сфер деятельности) языков
предстоит еще долгий путь. Однако шквал новых аббревиатур с окончанием
"ML" свидетельствует о несомненно прогрессивной (inventiveness) струе,
которую XML внес в науку, бизнес и образование.
Создавая новый язык
разметки на XML, его создатели должны договориться о трех вещах: какие там
будут теги, как они могут вкладываться друг в друга, и как они должны
обрабатываться. Первые два пункта - словарь языка и структура - кодируются
сейчас посредством DTD (Document Type Definition). Стандарт XML не
обязывает разработчиков языка прибегать к DTD, но у большинства новых
языков DTD-описания, по-видимому, будут - программистам так проще писать
программы, понимающие данную разметку и извлекающие из нее что-то
толковое. Нужны будут также комплекты руководств, где на человеческом
языке описаны значения всех тегов. Например, HTML имеет DTD-описание, но
по HTML есть и сотни страниц привычных руководств, с которыми сверяются
программисты, разрабатывая браузеры и другие программы для Web.
Эссе о стиле
Для пользователей главное - это что умеет
делать программа, а не то, что написано в ее описании. Как правило, люди
предпочитают, чтобы программы позволяли им видеть закодированную на языке
XML информацию в читабельном виде. Но в тегах самого XML нет никакой
специальной разметки, указывающей. как данные должны быть представлены на
экране или печатном листе.
Для публикаторов, стремящихся написать
однажды, а потом постоянно издавать ("write once and publish everywhere"),
самое главное - "родить" публикацию, а затем "разливать" ее в мириады
видов изданий, как печатных, так и электронных. XML помогает им так:
контент размечается описательными тегами, независимыми от среды
визуализации. Далее публикатор может оформить правила представления в виде
т. н. stylesheets (листов стилей), автоматически "стилизующих" его
произведение под разные устройства и среды. Стандарт такого XML-языка,
разрабатываемый для этих целей, носит название Extensible Stylesheet
Language (XSL).
Последние версии браузера умеют читать
XML-документы, выбирать соответствующие файлы стиля, и применять их для
сортировки и форматирования информации на экране. Читатель может даже и не
догадаться, что имеет дело с XML, а не HTML, если только не обратит
внимания, что сайты с XML шустрее и проще в использовании.
Люди с
недостатками зрения также получают бесплатный выигрыш от XSL-принципов
публикации документов, так как XSL дает им возможность читать XML в
системе Брэйля или с голоса. Эти преимущества касаются и остальных:
например, коммивояжеру, желающему заниматься сетевым серфингом, не выходя
из автомобиля, наверняка показалось бы довольно удобным слушать страницы в
звуковом сопровождении.
Хотя поначалу ядро Сети составляли научные
и образовательные программы, сегодняшняя Сеть - это уже коммерция (ну, или
можно сказать, коммерческие ожидания), запасающая топливо для быстрого
старта. Все помнят недавний резонанс, вызванный всплеском онлайновых
продаж, а стоит ли говорить о том, как стремительно взаимодействуют
бизнесмены в сети между собой. Потоки товаров крупных производителей так и
напрашиваются на автоматизацию в сети. Но в сегодняшних бизнес-схемах
используются сложные взаимодействия program-to-program, и на практике это
работает из рук вон плохо, ибо для успеха необходимо единообразие
процессов обработки, до которого пока еще далеко.
На протяжении
столетий люди успешно занимались бизнесом, обмениваясь типовыми
документами: заказами, счетами, декларациями, квитанциями и т.д. и т.д.
Документы работали на бизнес, и никто не требовал, чтобы одна участвующая
сторона знала внутреннюю кухню другой. Любой документ показывался ровно
настолько, насколько получателю информации следовало его показать, и не
более. По-видимому, обмен документами и есть самый правильный способ
заниматься бизнесом и в Web тоже. Но это вовсе не было той задачей, под
которую создавался HTML.
И наоборот, XML задуман именно с целью
обмена документами и очевидно, что основа электронной коммерции будет
опираться на соглашения, выраженные миллионами курсирующих по Internet
XML-документов.
Таким образом, Сеть, усиленная XML, должна стать
для своих пользователей быстрым, дружественным и лучшим местом для
бизнеса. Еще больше XML необходим web-мастерам и web-дизайнерам. "На
полную катушку" потребуется знание новых XML-языков армиям программистов.
И хотя дни самообразованных хакеров [авторы имели в виду лучший смысл
этого слова] еще длятся, над их популяцией уже нависла угроза.
Завтрашний web-дизайнер обязан быть сведущ не только в
изготовлении текста и графики, но и в строительстве многоуровневых,
взаимозависимых систем на основе DTD, деревьев данных, гиперссылочных
структурах, метаданных и стилевых компонентах - сильной и передовой
инфраструктуре Web второго поколения.
Я пытаюсь сделать несколько резюме моего опыта работы с XML:
Pros
Формат для чтения:
Каждый может проверить свой контент, просто прочитав его. Это делает его простой в использовании и понятной форме общения. Даже деловым людям нравится это (насколько я знаю в финансовых институтах в течение многих лет), поскольку они это понимают, и они могут легко проверять сообщения, например, в системах обмена сообщениями. Только они могут решить, какая система ошибается. Делает их счастливыми:) Сравните это с JSON . Я думаю, JSON далека от дружественной к читателю, поскольку закрытие скобок сложнее отслеживать, чем закрытие элементов в XML. Вы должны вернуться к странице, чтобы узнать, что было началом. Вам не нужны навыки программирования для понимания XML. Даже ваша бабушка может понять это через полчаса.
Независимость платформы:
Неважно, какой язык и платформа вы используете, у вас обязательно будет синтаксический анализатор, чтобы его прочитать. Это делает его, вероятно, лучшей формой связи между гетерогенными системами. Посмотрите, что люди обычно переносят XML файлы поверх очередей JMS, отправляют XML файлы в веб-службы, они переносят объекты в документы XML перед транспортировкой. XML - это настолько фундаментальный материал, что нет больших проблем с разными парсерами. Все они понимают XML.
Великие инструменты для преобразования
Отличный инструмент для проверки с помощью
Против
Многословность
Он может потреблять любое дисковое пространство. XML файлы делают журналы большими и трудными для чтения и извлечения. С другой стороны, вы можете сжимать журналы. Даже веб-службы или сообщения JMS могут быть сжаты, чтобы уменьшить нагрузку на канал. Но даже в этом случае сжатие - это издержки процессора и памяти. С другой стороны, в моем опыте XML и смежные технологии могут сократить развитие, и то, что вы экономите в мандатах, достаточно далеко, чтобы купить еще один процессор. Процессоры дешевле людей.
Неэффективное использование
Далеко не тривиально, какие объекты (выражения XPath, шаблоны XSL, схемы XSD, синтаксические анализаторы XML и т.д.) имеют какой жизненный цикл. Что можно кэшировать? Многие люди не делают это правильно, чтобы избежать проблем безопасности нитей. И это приведет вас к ужасной медлительности. И я хочу подчеркнуть, что это не проблема технологии, а неправильное использование
. Многие люди застряли в старом партере DOM, который является уродливым. Они абстрагировали некоторый слой над ним и создали собственные API для обработки XML, что плохо. Двигайтесь дальше, используйте DOM4j или STAX или JAXB или что-то стандартное.
Ложная свобода создания чего-то особенного
Многие компании создали языки, специфичные для домена, или ужасные конфигурационные файлы с XML. Поскольку это легко разобрать и пройти, они создали даже переводчиков для совершенно нового языка. Язык застрял, и запланированные инструменты разработки никогда не создавались. Никогда не используйте XML для создания программ. Его нельзя использовать. Не программируйте в XPath, так как это не проверенное время разработки. Держите вещи на месте. XML в основном предназначен для транспортировки данных в некоторой стандартной форме. Не изобретайте колесо в XML. Это было бы программным креслом для себя, а не автомобилем.
Лучшие учебники по XML находятся на ZVON Я думаю. Используйте их, если хотите.
Добавьте к этому и неудовлетворительное качество возможностей поиска в Web. Поскольку не существует способа как-то особо пометить информацию о ценах, решительно невозможно осуществлять в web поиск страниц по признаку "цена".
Что-то старое, что-то новое
В принципе, решение элементарно: в тегах нужно указывать, что это за информация, а не то, как она должна выглядеть. Например, размечать компоненты заказа на рубашку тегами "цена, размер, количество, цвет", а не "bold, paragraph, row, column", как это предлагается в HTML. Тогда программе проще идентифицировать документ как заказ и выполнить остальную часть работы: показать этот заказ в том или ином виде, провести через бухгалтерскую систему, или сделать все так, чтобы назавтра новая рубашка была бы доставлена к вашему порогу.
Мы, рабочая группа W3C, еще в 1996 г. приступили к разработке такого проекта. Идея была сильная, хотя и не совсем оригинальная. На протяжении поколений редакторы и печатники маркировали рукописные тексты пометками для наборщиков. Подобный "язык разметки" развивался самостийно до 1986г., пока, в результате десятилетней работы, Международная Организация по стандартизации (ISO) не ввела систему создания новых языков разметки.
Получив имя SGML (Standard Generalized Markup Language), этот язык описания языков - метаязык - доказал свою полезность на примере многих крупных систем подготовки публикаций. И даже HTML получил свое определение через SGML. Единственная трудность с SGML заключалась в его всеядности - там масса заумных вещей для минимизации нажатий на клавиши, так как в ту пору каждый байт был на счету. Вот почему сегодня web-браузеры с ним не в ладах.
Создавая XML, наша рабочая группа очистила SGML от всей шелухи и предложила строго-целевой и удобоваримый метаязык. Базой XML является набор правил, руководствуясь которыми, каждый может создать собственный язык разметки. Эти правила выбраны так, чтобы одна единственная небольшая программа (ее еще называют парсером или синтаксическим анализатором) могла справиться с распознаванием любого нового языка. Обратимся снова к примеру с доктором, который хотел бы передать анализы специалисту. Если бы врачи-профессионалы выстроили из XML свой язык разметки для кодирования врачебных записей (ряд групп уже давно работают над проблемой), то в сообщении доктора своему коллеге могло бы быть нечто вроде
<имя
пациента> blah blah
<аллергия на
лекарство> blah blah blah
В такой постановке уже не сложно написать программу для произвольно взятого компьютера так, чтобы она могла распознать эти стандартизованные врачебные записи и умела заносить эту в прямом смысле жизненно важную информацию в свою базу данных.
Точно так же, как HTML создавался, чтобы любой пользователь мог читать Internet-документы, XML дает нам то эсперанто, на котором любой может читать и писать, невзирая на вавилон несовместимых платформ. Да даже с точки зрения рядового человека в языке XML больше смысловой нагрузки (в отличие от других форматов данных), ибо в нем нет чего-то такого, что выглядело бы нечитабельным текстом.
Мощь универсальности XML обусловлена минимальным набором правильно выбранных правил. Во-первых - теги всегда составляют пару, окружая своеобразными скобками текст, к которому они применяются. Во-вторых - спаренные теги могут вкладываться друг в друга наподобие кавычек, позволяя выстраивать сложные многоуровневые структуры.
Правило вкладывания автоматически обуславливает простоту любого XML-документа, производя структуру, известную в информатике как дерево. Аналогично генеалогическому дереву, любой графический или текстовый элемент документа есть отец, сын или брат (parent, child, sibling) какого-то другого элемента, и это отношение родства всегда однозначно. Конечно, деревья не описывают все многообразие структур данных, однако покрывают большую часть типовых случаев применения компьютеров. Кроме того, деревья необычайно удобны для программистов. Нет проблем написать небольшой кусочек кода для переупорядочивания транзакций или вывода на экран вполне понятного чека, когда этот чек представлен в виде дерева.
Второй источник универсальной силы XML - это опора на
новый стандарт Unicode - систему кодирования, допускающую взаимосмешение
текстов на всех основных языках мира. Напротив, в HTML, как и в массе
текстовых процессоров, документ, как правило, может быть только на одном
конкретном языке, не важно каком - английском, японском или арабском.
А
если программа не знает кодировки какого-то языка, о документе (в HTML)
можно забыть. Бывает и хуже: к примеру, из-за несогласованности кодировок
программы, написанные на Тайване, часто не умеют читать тексты,
ориентированные на материковый Китай. В случае с XML, если программа умеет
правильно с ним работать, она справится с любой комбинацией кодировок.
Таким образом, XML позволяет обмениваться данными не только между разными
компьютерными платформами, но и дает возможность преодолевать национальные
и культурные барьеры.
Конец вселенскому ожиданию (World Wide Wait)
С распространением XML Сеть должна стать намного "отзывчивее". Сегодня все, что умеют делать компьютерные устройства в сети, не важно, мощные это десктопы или карманные органайзеры, это не больше, чем получить форму по "GET", заполнить ее, потом гонять на web-сервер туда-сюда, пока работа с формой не будет завершена. XML дает нам возможность передать в форму структуру и семантику данных, и, следовательно, все эти устройства смогут делать основную обработку в нужном месте и незамедлительно. Это не только уменьшит нагрузку на сервера, но и должно привести к существенному сокращению сетевого трафика.
Для иллюстрации представьте себе, как в онлайновом бюро путешествий вам нужно подобрать рейс из Лондона в Нью-Йорк на 4 июля. Скорее всего, вы увидите список в несколько раз длиннее, чем может поместиться на экране. Этот список можно сократить, задав более точные параметры типа времени вылета, цены или авиакомпании, но в этом случае вы просто "нагружаете" сервер бюро путешествий своим запросом и вынуждены дожидаться ответа. Однако если бы этот длинный список рейсов вам предоставили в XML, то бюро могло бы сопроводить его небольшим Java-аплетом, с помощью которого моментально и легко отсортировать и отсеять ненужное, не прибегая к какому-либо взаимодействию с сервером. Помножьте это на миллионы пользователей Web, и общий эффект окажется впечатляющим.
Чем больше сетевой информации будет размечено "отраслевыми" XML-тегами, тем легче будет найти то, что вы ищете. Сегодня поиск в Internet по запросу "работа для биржевого брокера" захлестнет вас лавиной рекламных объявлений, но вероятно, о работе их там будет всего несколько штук - в основном работа прячется на бесплатных досках объявлений газетных сайтов, с которыми не любят работать поисковые роботы. И сейчас Ассоциация Газет Америки (Newspaper Association of America) создает на XML свой язык разметки объявлений, обещающий сделать процесс поиска намного эффективнее.
Неважно, пусть это просто промежуточный шаг. Библиотекари давно знают способы найти что-то быстро - просматривать не документы, а их компактные ключевые описания, лишь указывающие на сами источники. А именно, это каталоги с образцом в виде библиотечных карточек. Подобную информацию об информации и называют "метаданные".
Поэтому с самого начала важная роль в XML-проекте отводилась созданию сопутствующего стандарта метаданных. Ту же самую роль, как каталожные карточки для библиотечных книг, для информации в Web должна сыграть февральская Спецификация Описаний Ресурсов (Resource Description Framework, RDF). Распространяясь по Сети, метаданные RDF сделают поиск намного более быстрым и релевантным, чем сейчас. В Сети нет библиотекарей, но каждый веб-мастер, ко всему прочему, стремится к легкой "находимости" его сайта, поэтому мы ожидаем, что RDF, как только людям откроется его мощь, окажет огромное влияние на развитие Internet.
Разумеется, информацию можно получать и без поиска. В конце концов, Сеть это гипертекст - миллиарды страниц, пронизанных гиперссылками - теми подчеркнутыми словами, по которым достаточно щелкнуть, чтобы умчаться на какую-то другую страницу. В XML механизм гиперссылок так же многократно усилен. Спецификация ссылок в XML, называемая XLink и которую W3C готовит к концу года, даст возможность пользователю выбирать из нескольких адресов назначения. Еще одна разновидность гиперссылок позволит получать текст или изображение прямо по месту нажатия, давая возможность посетителю не покидать страницу.
Вероятно, полезнее всего в XLink окажется та часть спецификации, которая позволяет авторам прибегать к опосредованным ссылкам, отсылающим вместо самих страниц в некую сводную БД. Так, если автор изменил адрес страницы, простым авторским редактированием одной записи в такой базе данных легко обновить все ссылки, ведущие на его страницу. Это позволит избавиться от становящихся привычными сообщений "404 File Not Found", сигнализирующих о "сломавшейся" ссылке.
Сочетание более эффективной обработки, более точного поиска и более гибкого связывания революционизирует структуру Сети и открывает совершенно новые методы доступа к информации. Для пользователей эта новая Сеть станет существенно быстрее, мощнее и полезнее, чем Сеть сегодняшняя.
Необходимо сотрудничество
Разумеется, не все так просто. XML позволяет любому сконструировать новый язык на свой лад, однако создать хороший язык - задача, сложность которой не следует недооценивать. Придумать язык - лишь самое начало: наивно ожидать, что значения ваших тегов будут очевидны другим людям, пока вы не снабдили язык руководством, и будут понятны компьютерам, пока вы не написали программы, работающих с тегами языка.
Нетрудно объяснить, почему это так. Если бы все необходимое для того, чтобы научить компьютер обрабатывать заказы, сводилось к разметке тегами, тогда и XML не понадобился бы. Не нужны были бы даже программисты - раз компьютеры достаточно умны, чтобы уметь все делать самостоятельно.
То, зачем нам нужен XML, это не магия, а результативность. XML устанавливает базовые правила, на один пласт упрощающие детали программирования - чтобы люди со сходными интересами могли сконцентрироваться на другом твердом орешке - соглашениях о том, как именно они хотели бы оформлять данные, которыми им хотят обмениваться. Это очень непростая проблема, хотя и не новая.
И такие соглашения будут, поскольку множащаяся несовместимость компьютерных платформ дает нам в результате задержки сроков, финансовые потери и ведет к неразберихе почти во всех сферах деятельности. Люди хотят обмениваться идеями и делать дело, независимо от того, что у всех разные компьютеры - и чтобы это стало реальностью, взаиморазвитию частных (для разных сфер деятельности) языков предстоит еще долгий путь. Однако шквал новых аббревиатур с окончанием "ML" свидетельствует о несомненно прогрессивной (inventiveness) струе, которую XML внес в науку, бизнес и образование.
Создавая новый язык разметки на XML, его создатели должны договориться о трех вещах: какие там будут теги, как они могут вкладываться друг в друга, и как они должны обрабатываться. Первые два пункта - словарь языка и структура - кодируются сейчас посредством DTD (Document Type Definition). Стандарт XML не обязывает разработчиков языка прибегать к DTD, но у большинства новых языков DTD-описания, по-видимому, будут - программистам так проще писать программы, понимающие данную разметку и извлекающие из нее что-то толковое. Нужны будут также комплекты руководств, где на человеческом языке описаны значения всех тегов. Например, HTML имеет DTD-описание, но по HTML есть и сотни страниц привычных руководств, с которыми сверяются программисты, разрабатывая браузеры и другие программы для Web.
Эссе о стиле
Для пользователей главное - это что умеет делать программа, а не то, что написано в ее описании. Как правило, люди предпочитают, чтобы программы позволяли им видеть закодированную на языке XML информацию в читабельном виде. Но в тегах самого XML нет никакой специальной разметки, указывающей. как данные должны быть представлены на экране или печатном листе.
Для публикаторов, стремящихся написать однажды, а потом постоянно издавать ("write once and publish everywhere"), самое главное - "родить" публикацию, а затем "разливать" ее в мириады видов изданий, как печатных, так и электронных. XML помогает им так: контент размечается описательными тегами, независимыми от среды визуализации. Далее публикатор может оформить правила представления в виде т. н. stylesheets (листов стилей), автоматически "стилизующих" его произведение под разные устройства и среды. Стандарт такого XML-языка, разрабатываемый для этих целей, носит название Extensible Stylesheet Language (XSL).
Последние версии браузера умеют читать XML-документы, выбирать соответствующие файлы стиля, и применять их для сортировки и форматирования информации на экране. Читатель может даже и не догадаться, что имеет дело с XML, а не HTML, если только не обратит внимания, что сайты с XML шустрее и проще в использовании.
Люди с недостатками зрения также получают бесплатный выигрыш от XSL-принципов публикации документов, так как XSL дает им возможность читать XML в системе Брэйля или с голоса. Эти преимущества касаются и остальных: например, коммивояжеру, желающему заниматься сетевым серфингом, не выходя из автомобиля, наверняка показалось бы довольно удобным слушать страницы в звуковом сопровождении.
Хотя поначалу ядро Сети составляли научные и образовательные программы, сегодняшняя Сеть - это уже коммерция (ну, или можно сказать, коммерческие ожидания), запасающая топливо для быстрого старта. Все помнят недавний резонанс, вызванный всплеском онлайновых продаж, а стоит ли говорить о том, как стремительно взаимодействуют бизнесмены в сети между собой. Потоки товаров крупных производителей так и напрашиваются на автоматизацию в сети. Но в сегодняшних бизнес-схемах используются сложные взаимодействия program-to-program, и на практике это работает из рук вон плохо, ибо для успеха необходимо единообразие процессов обработки, до которого пока еще далеко.
На протяжении столетий люди успешно занимались бизнесом, обмениваясь типовыми документами: заказами, счетами, декларациями, квитанциями и т.д. и т.д. Документы работали на бизнес, и никто не требовал, чтобы одна участвующая сторона знала внутреннюю кухню другой. Любой документ показывался ровно настолько, насколько получателю информации следовало его показать, и не более. По-видимому, обмен документами и есть самый правильный способ заниматься бизнесом и в Web тоже. Но это вовсе не было той задачей, под которую создавался HTML.
И наоборот, XML задуман именно с целью обмена документами и очевидно, что основа электронной коммерции будет опираться на соглашения, выраженные миллионами курсирующих по Internet XML-документов.
Таким образом, Сеть, усиленная XML, должна стать для своих пользователей быстрым, дружественным и лучшим местом для бизнеса. Еще больше XML необходим web-мастерам и web-дизайнерам. "На полную катушку" потребуется знание новых XML-языков армиям программистов. И хотя дни самообразованных хакеров [авторы имели в виду лучший смысл этого слова] еще длятся, над их популяцией уже нависла угроза.
Завтрашний web-дизайнер обязан быть сведущ не только в изготовлении текста и графики, но и в строительстве многоуровневых, взаимозависимых систем на основе DTD, деревьев данных, гиперссылочных структурах, метаданных и стилевых компонентах - сильной и передовой инфраструктуре Web второго поколения.
Я пытаюсь сделать несколько резюме моего опыта работы с XML:
Pros
Формат для чтения:
Каждый может проверить свой контент, просто прочитав его. Это делает его простой в использовании и понятной форме общения. Даже деловым людям нравится это (насколько я знаю в финансовых институтах в течение многих лет), поскольку они это понимают, и они могут легко проверять сообщения, например, в системах обмена сообщениями. Только они могут решить, какая система ошибается. Делает их счастливыми:) Сравните это с JSON . Я думаю, JSON далека от дружественной к читателю, поскольку закрытие скобок сложнее отслеживать, чем закрытие элементов в XML. Вы должны вернуться к странице, чтобы узнать, что было началом. Вам не нужны навыки программирования для понимания XML. Даже ваша бабушка может понять это через полчаса.
Независимость платформы:
Неважно, какой язык и платформа вы используете, у вас обязательно будет синтаксический анализатор, чтобы его прочитать. Это делает его, вероятно, лучшей формой связи между гетерогенными системами. Посмотрите, что люди обычно переносят XML файлы поверх очередей JMS, отправляют XML файлы в веб-службы, они переносят объекты в документы XML перед транспортировкой. XML - это настолько фундаментальный материал, что нет больших проблем с разными парсерами. Все они понимают XML.
Великие инструменты для преобразования
Отличный инструмент для проверки с помощью
Против
Многословность
Он может потреблять любое дисковое пространство. XML файлы делают журналы большими и трудными для чтения и извлечения. С другой стороны, вы можете сжимать журналы. Даже веб-службы или сообщения JMS могут быть сжаты, чтобы уменьшить нагрузку на канал. Но даже в этом случае сжатие - это издержки процессора и памяти. С другой стороны, в моем опыте XML и смежные технологии могут сократить развитие, и то, что вы экономите в мандатах, достаточно далеко, чтобы купить еще один процессор. Процессоры дешевле людей.
Неэффективное использование
Далеко не тривиально, какие объекты (выражения XPath, шаблоны XSL, схемы XSD, синтаксические анализаторы XML и т.д.) имеют какой жизненный цикл. Что можно кэшировать? Многие люди не делают это правильно, чтобы избежать проблем безопасности нитей. И это приведет вас к ужасной медлительности. И я хочу подчеркнуть, что это не проблема технологии, а неправильное использование . Многие люди застряли в старом партере DOM, который является уродливым. Они абстрагировали некоторый слой над ним и создали собственные API для обработки XML, что плохо. Двигайтесь дальше, используйте DOM4j или STAX или JAXB или что-то стандартное.
Ложная свобода создания чего-то особенного
Многие компании создали языки, специфичные для домена, или ужасные конфигурационные файлы с XML. Поскольку это легко разобрать и пройти, они создали даже переводчиков для совершенно нового языка. Язык застрял, и запланированные инструменты разработки никогда не создавались. Никогда не используйте XML для создания программ. Его нельзя использовать. Не программируйте в XPath, так как это не проверенное время разработки. Держите вещи на месте. XML в основном предназначен для транспортировки данных в некоторой стандартной форме. Не изобретайте колесо в XML. Это было бы программным креслом для себя, а не автомобилем.
Лучшие учебники по XML находятся на ZVON Я думаю. Используйте их, если хотите.